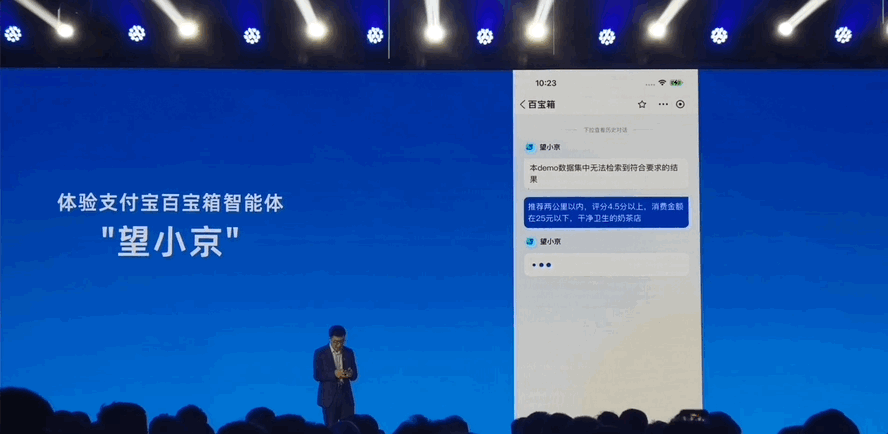
7天开发一个AI Agent应用!秘密武器:一体化数据库
7天开发一个AI Agent应用!秘密武器:一体化数据库几个工程师、一个星期,就能做一个AI Agent应用了。 效果be like—— 能理解用户复杂长命令,推荐符合要求的奶茶店。
来自主题: AI资讯
5811 点击 2024-10-25 10:18
 搜索
搜索
几个工程师、一个星期,就能做一个AI Agent应用了。 效果be like—— 能理解用户复杂长命令,推荐符合要求的奶茶店。

工具调用是 AI 智能体的关键功能之一,AI 智能体根据场景变化动态地选择和调用合适的工具,从而实现对复杂任务的自动化处理。例如,在智能办公场景中,模型可同时调用文档编辑工具、数据处理工具和通信工具,完成文档撰写、数据统计和信息沟通等多项任务。

为应对公司在大规模文本、图像等非结构化数据处理上的业务增长需求,笔者着手调研当前流行的开源向量数据库。主要针对查询速度、并发度和召回率这几大核心维度进行深入分析,以确保选定的数据库方案能够在实际业务场景中高效应对大规模数据检索和高并发需求。通过全面对比不同数据库的表现,得出可靠的调研结论。

目前,机器人的训练数据大体上可分为三类:第一类是真实的遥操数据,第二类是高质量的仿真合成数据,第三类是人类的行为数据、其主要源于互联网视频。

在人形机器人领域,有一个非常值钱的问题:既然人形机器人的样子与人类类似,那么它们能使用网络视频等数据进行学习和训练吗?

现有的大模型主要依赖固定的参数和数据来存储知识,一旦训练完成,修改和更新特定知识的代价极大,常常因知识谬误导致模型输出不准确或引发「幻觉」现象。因此,如何对大模型的知识记忆进行精确控制和编辑,成为当前研究的前沿热点。

Time-MoE采用了创新的混合专家架构,能以较低的计算成本实现高精度预测。研发团队还发布了Time-300B数据集,为时序分析提供了丰富的训练资源,为各行各业的时间序列预测任务带来了新的解决方案。

RAG通过纳入外部文档可以辅助LLM进行更复杂的推理,降低问题求解所需的推理深度,但由于文档噪声的存在,其提升效果可能会受限。中国人民大学的研究表明,尽管RAG可以提升LLM的推理能力,但这种提升作用并不是无限的,并且会受到文档中噪声信息的影响。通过DPrompt tuning的方法,可以在一定程度上提升LLM在面对噪声时的性能。

AI的发展,未来会不会干掉在线旅游的OTA模式? 就着这一话题,美国科技创投公司Altimeter Capital的合伙人Thomas Reiner特地撰文,深入分析OpenAI的ChatGPT旅游预订,在库存、数据、服务、可视化、隐私、延迟、价格、代理、监管等维度上的优势和劣势。 他设想了OTA与AI未来发展的3个可能性,其中不乏趣味与洞察。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。