美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源
美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。
来自主题: AI资讯
9347 点击 2024-12-02 12:35
 搜索
搜索
Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。

“明天去北京出差适合穿什么衣服?明天的天气适合晨跑吗?”11月29日,中国气象局华风气象传媒集团(以下简称:中国气象局)联合支付宝推出首个国家级天气智能体“中国天气小助手”,由中国气象局提供权威气象数据,可为用户提供“查天气、穿衣推荐、气象科普等”多种气象领域服务,用户在支付宝首页下拉或下载支小宝APP即可使用。

本周五,知名 AI 领域学者,OpenAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 发表观点:「人们对『向人工智能询问某件事』的解释过于夸张」,引发网友热议。

CRM作为企业软件中最大的板块之一,其价值毋庸置疑。传统CRM的本质是关系型数据库,在AI尤其是多模态技术的加成下,CRM从结构化数据向半结构化/非结构化数据的转变势在必行。
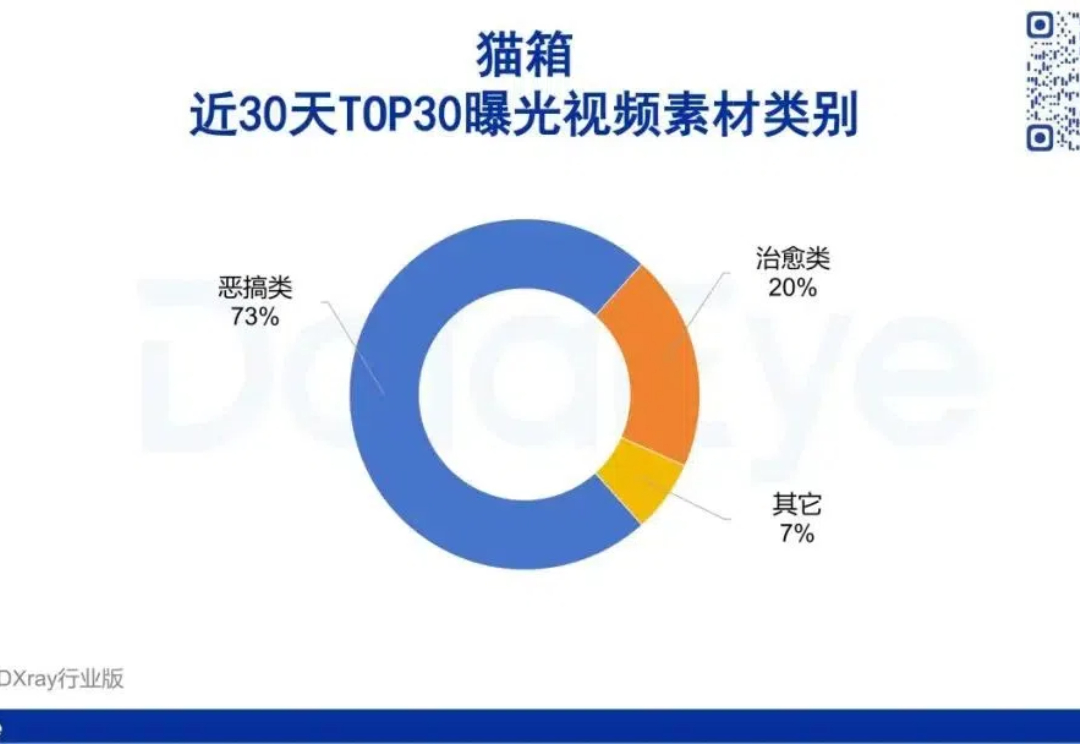
数据显示,2024年10月,MiniMax旗下海外社交AI产品Talkie月活达2062万,对应的国内版产品“星野”月活也达到了512万,位居国内社交AI榜首。

代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!
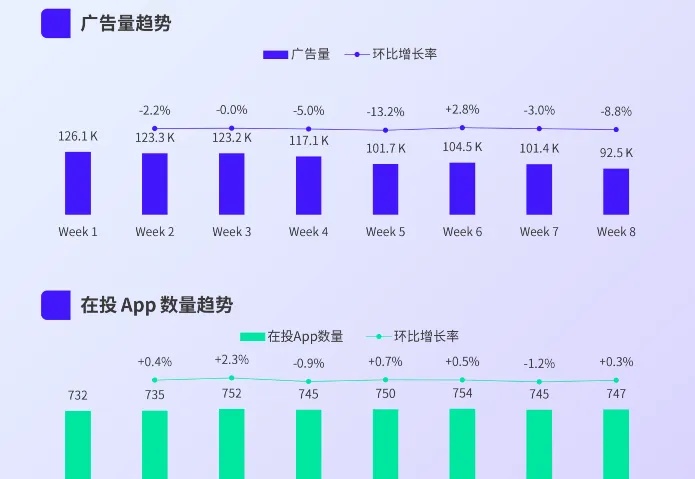
海外 AI 应用市场在去年迎来爆发式增长,势头一直延续至今。经过一年多的发酵,海外 AI 应用市场发展到何种阶段?本文将以 AppGrowing 国际版 所追踪到的 2024 年 9~10 月 AI 类应用海外移动广告数据为依托,从 AI 类应用的海外投放趋势、头部产品竞争格局和广告创意素材等方面,分析近期 AI 类应用的海外买量情况和市场发展趋势。
命运齿轮转动的开始,源于 2023 年的 3 月 23 日的 OpenAI 一次日常更新。

这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。
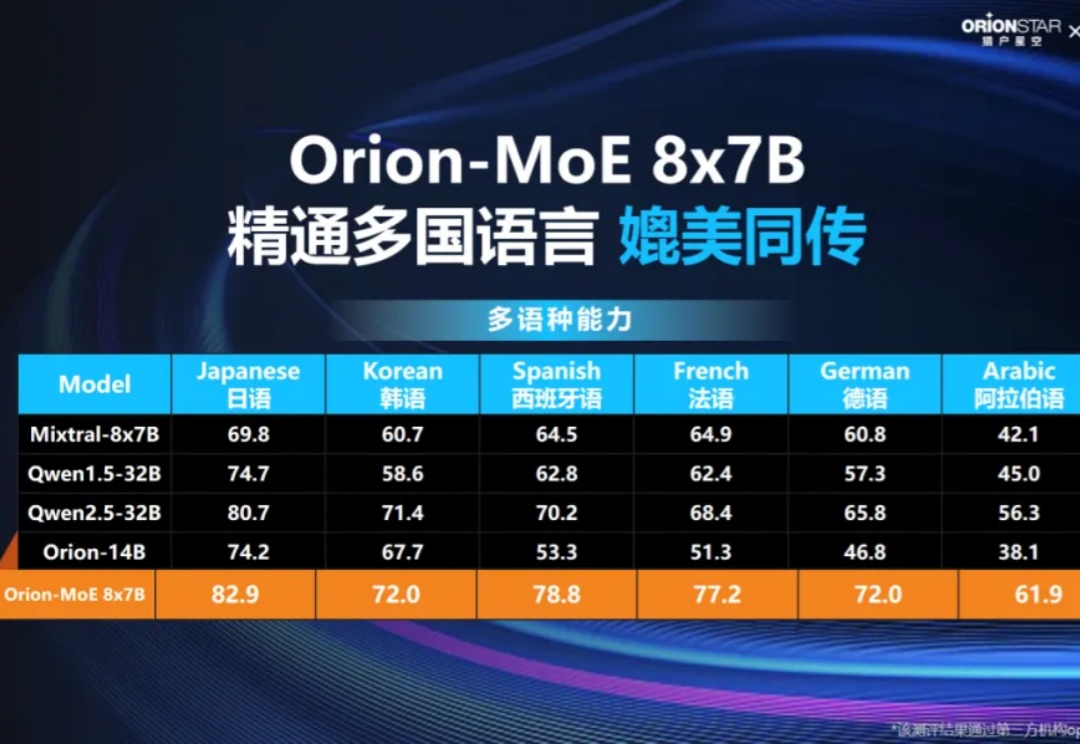
11月27日,猎户星空联合聚云科技举办了题为《Data Ready for Al,MoE大模型发布暨商业闭环分享》媒体见面会。猎户星空正式发布了自主研发的Orion-MoE 8×7B大模型,并携手聚云科技推出了基于该大模型的数据服务—AI数据宝AirDS(AI-Ready Data Service)。