
发力数据标注服务,Uber也想成为AI圈的“卖水人”
发力数据标注服务,Uber也想成为AI圈的“卖水人”自2022年年末OpenAI发布ChatGPT以来,英伟达的市值就上涨了近5倍,甚至超越苹果成为了全球最值钱的公司。眼看着英伟达如今能够让OpenAI、Meta、xAI等一众AI厂商排队交钱,也就使得越来越多的公司想成为此次AI淘金热中的“卖水人”。
来自主题: AI资讯
8848 点击 2024-12-20 09:39
 搜索
搜索
自2022年年末OpenAI发布ChatGPT以来,英伟达的市值就上涨了近5倍,甚至超越苹果成为了全球最值钱的公司。眼看着英伟达如今能够让OpenAI、Meta、xAI等一众AI厂商排队交钱,也就使得越来越多的公司想成为此次AI淘金热中的“卖水人”。

面对AI圈疯传的「数据如化石燃料一般正在枯竭」,我们该如何从海量数据中掘金?AI炼出的数据飞轮2.0,或许就是答案。

大模型的开源与闭源之争至今仍是热议话题,毕竟讨论核心触及技术发展路径、产业生态构建,以及对未来创新动力的影响。
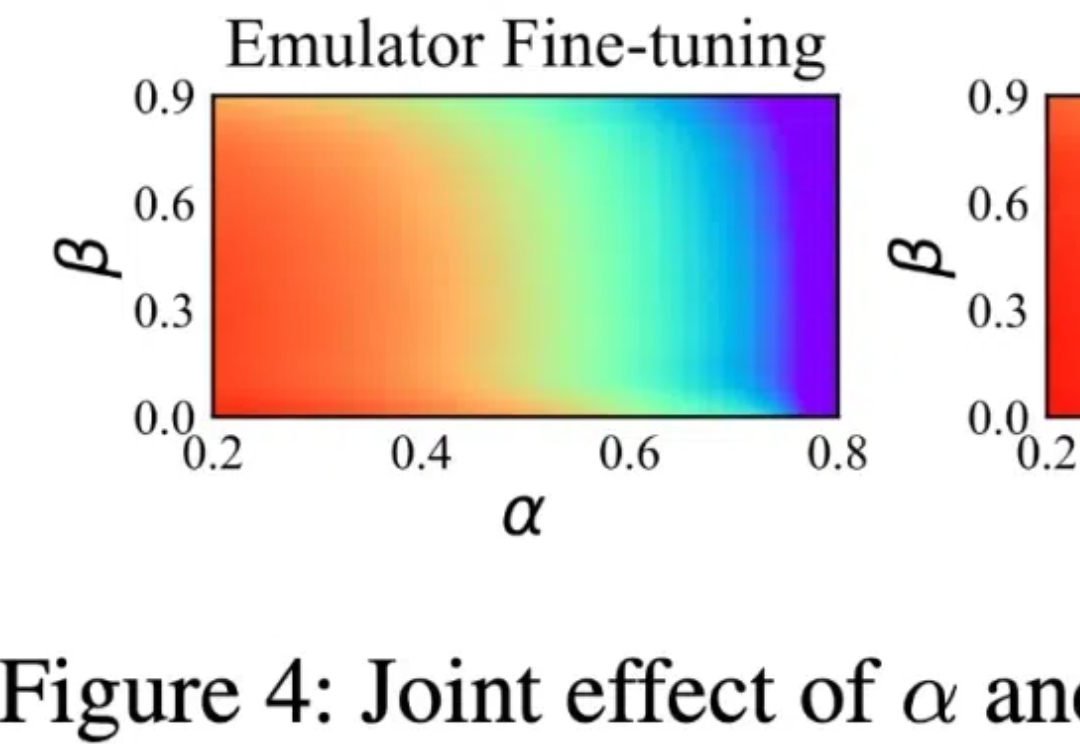
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。

清华大学与国家蛋白质科学中心的最新成果,结合了稳定学习的理论,提出了一个面向多中心、大队列异质数据的「稳定」生存分析方法。
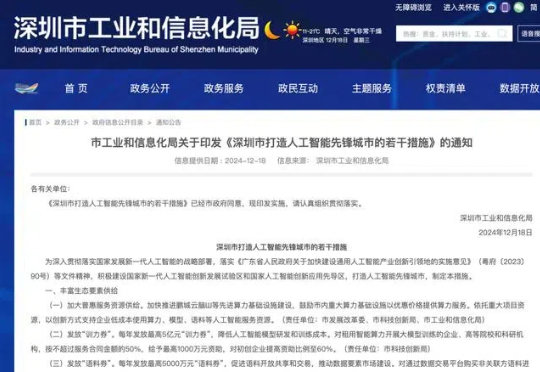
12月18日,记者从深圳市工业和信息化局了解到,深圳拟出台若干措施,积极建设国家新一代人工智能创新发展试验区和国家人工智能创新应用先导区,打造人工智能先锋城市。其中,在丰富生态要素供给方面,每年发放最高5亿元“训力券”,降低人工智能模型研发和训练成本。同时每年发放最高5000万元“语料券”,促进语料开放共享和交易,推动数据要素市场建设。
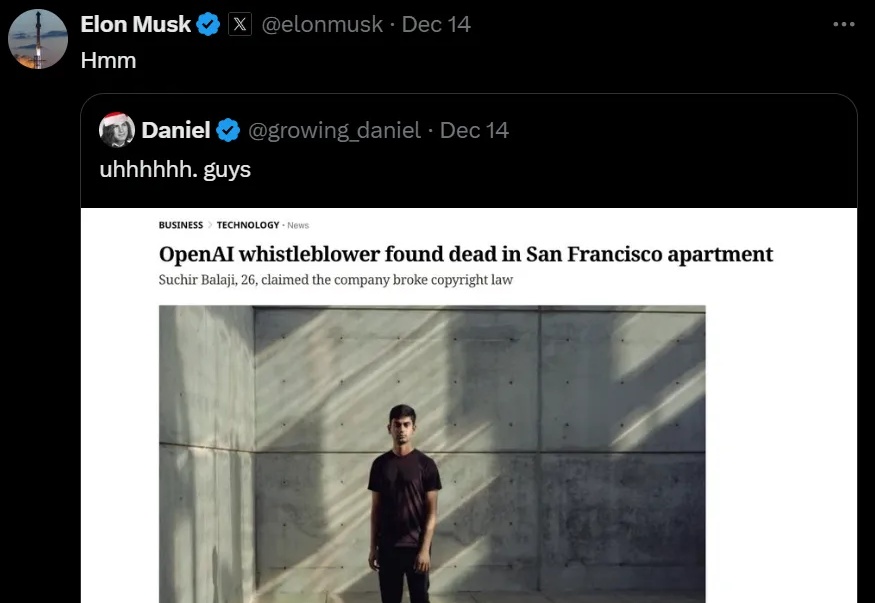
曾任OpenAI核心研发者的Suchir Balaji,于10月发文直指ChatGPT等生成式AI违背「合理使用」原则。然而,上月底26岁的他被发现离世,疑为自杀。马库斯发文悼念,称Suchir是个勇敢的年轻人,他对AI训练数据的版权问题提出的担忧「切中要害」。

智东西12月18日报道,单轮融资超700亿元!已搞定近9成,这是刚刚诞生的全球AI创企融资新纪录。

智东西12月17日报道,近日,估值达140亿美元的硅谷AI数据标注独角兽Scale AI被其数据标注工人诉上法庭,其华人创始人、全球最年轻的白手起家亿万富翁之一Alexandr Wang也被列为被告。

LLM 强大的语言能力,使其被广泛部署于 LLM 应用系统(LLM-integrated applications)中。此时,LLM 需要访问外部数据(如文件,网页,API 返回值)来完成任务。