
马斯克曝光Grok 5!1.5万亿参数,偷师Cursor狂练编程
马斯克曝光Grok 5!1.5万亿参数,偷师Cursor狂练编程马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
来自主题: AI资讯
8701 点击 2026-05-26 16:51
 搜索
搜索
马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
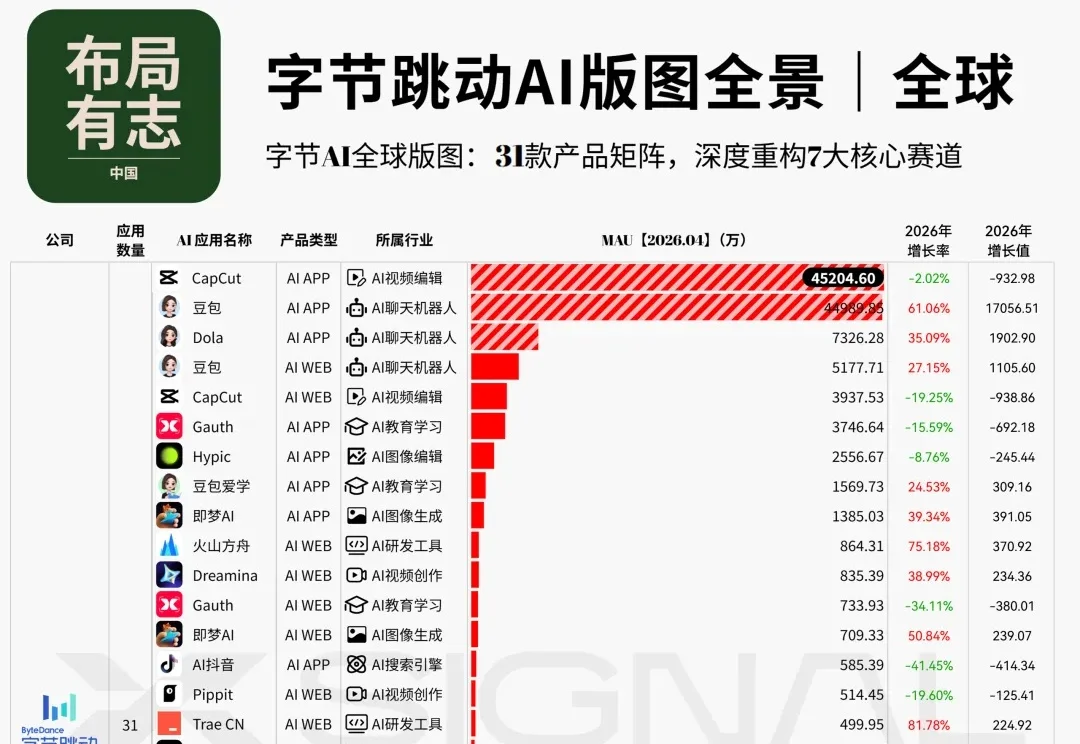
字节跳动计划在今年将其在人工智能基础设施上的支出大幅提升惊人的25%。这意味着将投入2000亿元人民币,这可不是一个边缘性的微调,是一次由不断升级的存储芯片成本以及字节跳动想要主导AI领域的雄心共同推动的巨大升级。
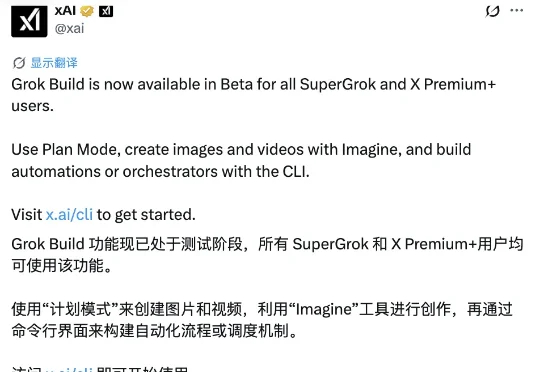
马斯克在X上发帖透露,xAI自家的Grok基础模型V9-Medium(1.5T)已经完成训练。预计再过2到3周,差不多就能正式对外发布啦:马斯克特意提到,V9-Medium的补充训练中加入了大量Cursor数据,后续还会继续添加。

亚马逊给员工的AI工具装了计量器,官方说不考核,经理盯着排行榜不放。Meta内部榜单30天烧掉60万亿token,扎克伯格没进前250。然而Jellyfish数据打脸:刷10倍token,产出只多了1倍。谁在为这场荒诞游戏推波助澜?
根据 Sensor Tower 发布的《2026 年全球 AI 应用趋势洞察》,2026 年第一季度,全球 AI 图像视频生成 App 的内购收入达到 1.5 亿美元,环比增长 20%,下载量达到 1.7 亿次,环比增长 12%,均超双位数。

在红杉资本AI Ascent2026峰会的舞台上,Starcloud联合创始人兼CEO Philip Johnston带来了一场堪称“戴森球雏形”的震撼演讲,论证了为什么“AI 计算的未来在地球轨道上”。Philip Johnston被视为“太空AI计算”这一前沿领域的开拓者,致力于通过向地球轨道部署卫星数据中心,解决地球上 AI 算力带来的能源瓶颈。
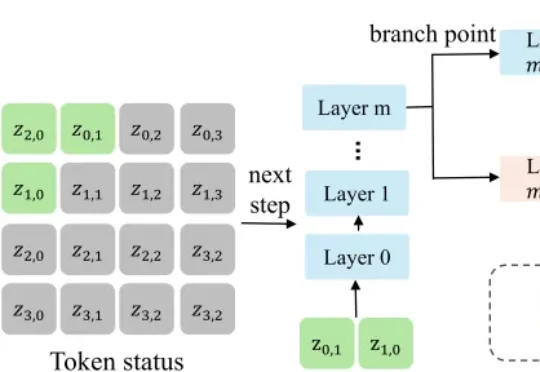
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

5 月 20 日,武汉光谷。极佳视界(GigaAI)在「家庭场景子品牌发布会暨物理通用智能技术发布会」上,给出了一份相对完整的答案。这场发布会公布了五件事:全球首个物理 AGI「双金字塔」体系;家庭场景子品牌「拾光 SeeLight」与首款家庭通用人形机器人「拾光 S1」同步亮相;国内首个真实家庭场景百台部署落地武汉,Q3 起规模化运营;

重庆一家科技公司就推出了一个起床神器:「Sunflower X AI唤醒灯」。在现代社会,手机闹钟几乎零成本,但一盏功能类似的台灯,却要319美元(约合人民币2168元),而这还是他们在Kickstarter上的早鸟价。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。