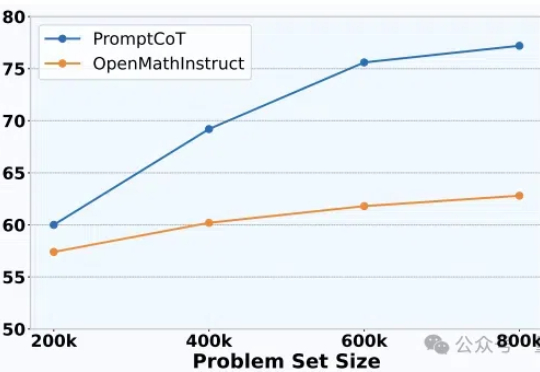
AI能自主出“竞赛题”了!港大&蚂蚁让大模型学会生成难题,水平已接近AIME
AI能自主出“竞赛题”了!港大&蚂蚁让大模型学会生成难题,水平已接近AIME大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。
来自主题: AI技术研报
9583 点击 2025-03-15 15:39
 搜索
搜索
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

南洋理工大学的研究团队提出了MedRAG模型,通过结合知识图谱推理增强大语言模型(LLM)的诊断能力,显著提升智能健康助手的诊断精度和个性化建议水平。MedRAG在真实临床数据集上表现优于现有模型,准确率提升11.32%,并具备良好的泛化能力,可广泛应用于不同LLM基模型。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。

今天一大早,ChatGPT突然更新——基于Python的数据分析功能,在o1和o3-mini当中也可以使用了。OpenAI介绍,现在可以通过两款模型调用Python,完成数据分析、可视化、基于场景的模拟等任务。
以业务解构技术,搭好数据“地基”。

洛杉矶初创公司 Moonvalley 推出了一款 AI 视频生成模型,该公司声称这是少数基于公开许可(非版权)数据训练的模型之一。
ChatGPT等AI模型爆发式增长引发关键问题:这场AI革命需要消耗多少能源?本文探究数据中心在乡村地区的快速扩张,以弗吉尼亚州为例,揭示研究者如何通过供应链分析和直接测量两种方法估算AI能耗。

近日,北京大学智能学院袁晓如课题组在中国古籍内容的智能探索方面开展跨学科合作探索取得重要进展。研究通过智能自动分类机制,从大量中国古籍中提取可视化图像,建立大规模中国古代可视化集合