
52页PPT,谷歌Gemini预训练负责人首次揭秘!扩展定律最优解
52页PPT,谷歌Gemini预训练负责人首次揭秘!扩展定律最优解大模型之战烽火正酣,谷歌Gemini 2.5 Pro却强势逆袭!Gemini Flash预训练负责人亲自揭秘,深挖Gemini预训练的关键技术,看谷歌如何在模型大小、算力、数据和推理成本间找到最优解。
来自主题: AI技术研报
9629 点击 2025-04-29 09:43
 搜索
搜索
大模型之战烽火正酣,谷歌Gemini 2.5 Pro却强势逆袭!Gemini Flash预训练负责人亲自揭秘,深挖Gemini预训练的关键技术,看谷歌如何在模型大小、算力、数据和推理成本间找到最优解。
2023 年 7 月份,我们曾经观察过妙鸭相机靠 AI 写真功能一炮而红,又快速陨落的全过程。而在产品数据下滑的同时,同年 11 月 13 日,妙鸭相机对外确认,产品负责人张月光离职。
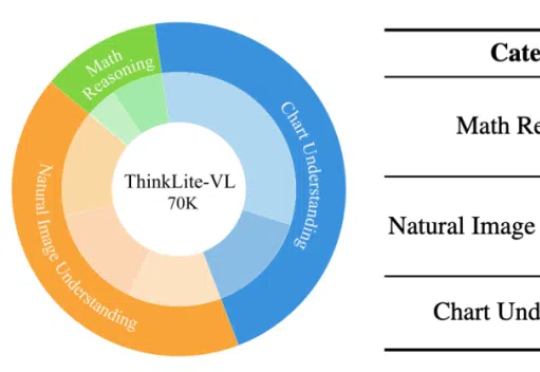
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。

追星分泌多巴胺,却也伴随大量做数据等考验精神耐力和体力的绝望劳动。应援、做数据,为自担辗转各大平台控评,以及为每一次线下见面设计应援物,每一项都耗损心神,靠饭圈女孩用爱发电。 随着AI生成图文的功能强大,一些饭圈女孩被解救出来。
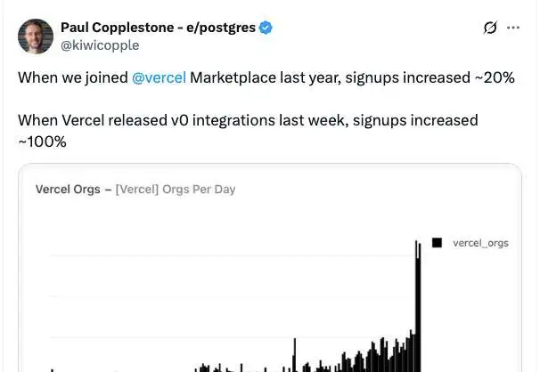
本周,Supabase 的发展已经迎来高光时刻:据《财富》杂志报道, Supabase 宣布完成 2 亿美元 D 轮融资,投后估值 20 亿美元。本轮由 Accel 领投,Coatue、Y Combinator、Craft Ventures 及老股东 Felicis 参投。距离其上一轮 8000 万美元融资仅过去 7 个月,累计融资已达近 4 亿美元。

自 OpenAI 发布 chatgpt 以来,业内除了技术公司、媒体公司比较关注其进展以外,还有一个行业比较关注,那就是战略咨询行业。尤其是最近 GPT-4o、Claude 3.7 Sonnet 为代表的最新大模型在数据分析、内容生成、编码和复杂推理方面展现出强大能力,与战略咨询工作的核心环节高度相关 。

近日,微软发布了2025年度《工作趋势指数》报告,该研究调查了来自31个国家和地区的3.1万名受访者,并整合了LinkedIn就业市场数据,分析了AI和数字化转型对全球工作环境和组织结构的深刻影响,并预测了一个新的概念——“前沿企业”(Frontier Firms)。这些公司利用AI助手和人类智能的融合,推动了快速发展、灵活运营和价值创造。

年初,DeepSeek 上线,18 天内即获得了 1600 万次下载,登顶 140 国下载榜单。让人意料之外而又情理之中的是,AI最火的功能不是翻译、写作,而是算命。有数据显示,#DeepSeek 算命等话题在小红书上吸引了超过 6600 万次浏览。

近期,一款 AI 浏览器产品 Fellou 在各大 AI 用户社群、媒体测评内容中陆续出现,受到热议与关注。Fellou 官方给出的定位是全球首个 Agentic Browser,一款基于 AI 技术的新型浏览器。Fellou 的核心亮点在于,用户只需一句话,Fellou 就能自动解析指令并跨多个网页和系统调度操作,从数据采集、表单填写到报告生成,实现一站式无缝交付。
全球首个去中心化强化学习训练的32B模型——INTELLECT-2震撼发布!无需授权,就能用自家异构计算资源参与其中,让编码、数学与科学领域的推理性能迈向新高度。