
英伟达让机器人「做梦学习」,靠梦境实现真·从0泛化
英伟达让机器人「做梦学习」,靠梦境实现真·从0泛化「仿生人会梦见电子羊吗?」这是科幻界一个闻名遐迩的问题。现在英伟达给出答案:Yes!而且还可以从中学习新技能。如下面各种丝滑操作,都没有真实世界数据作为训练支撑。仅凭文本指令,机器人就完成相应任务。
来自主题: AI资讯
8801 点击 2025-05-22 13:44
 搜索
搜索
「仿生人会梦见电子羊吗?」这是科幻界一个闻名遐迩的问题。现在英伟达给出答案:Yes!而且还可以从中学习新技能。如下面各种丝滑操作,都没有真实世界数据作为训练支撑。仅凭文本指令,机器人就完成相应任务。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!

DeepSeek依旧牢牢占据中国AI产品访问量第一的宝座,其月访问量甚至超过其他几款主流产品的总和。相比之下,腾讯「元宝」和「Kimi」的流量则出现明显下滑,环比降幅超过20%。在广告投放趋于保守之后,用户增长逐步放缓,流量更加依赖产品本身的可用性和用户黏性。
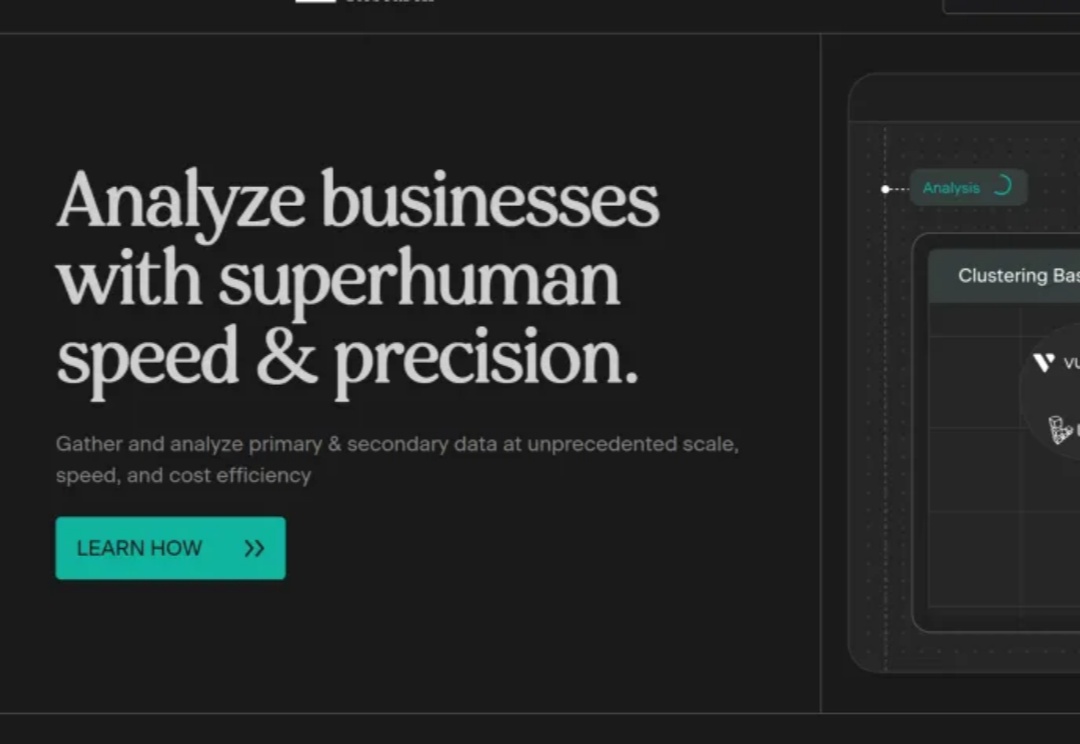
与当前大部分AI+research产品的关注点不同,Bridgetown Research通过AI赋能市场调查中的专家访谈、竞品对比以及数据分析的全过程,从二手数据开始,结合领域专家的知识框架提出关键假设,AI通过联系专家和客户进一步收集原始数据并进行分析,完成最终报告,极大缩减尽职调查所需的时间成本。

得益于AI上下文和审美能力的提升,现在做HTML已经没什么门槛了,可以应用到很多方面,例如小红书封面、PPT、原型图、数据看板等等。
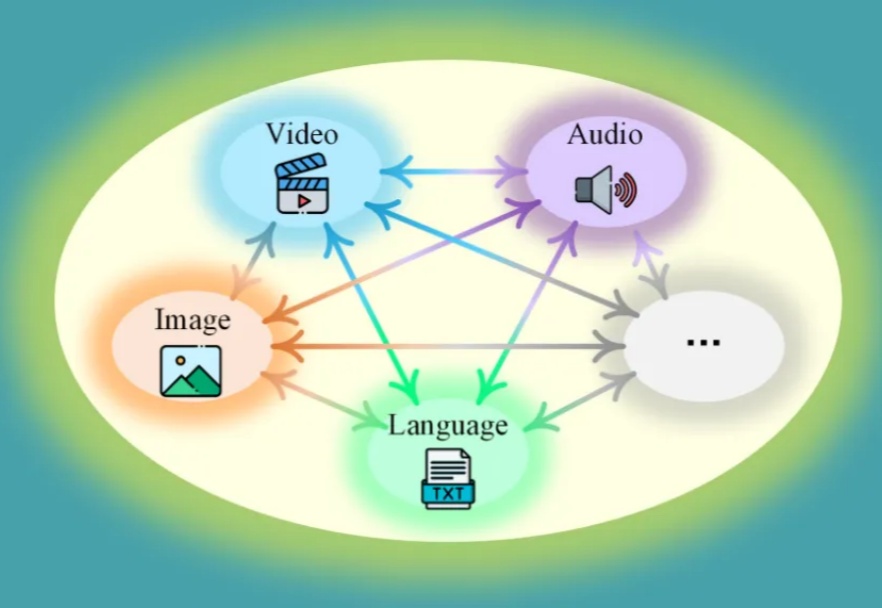
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
「Scaling Law 即将撞墙。」这一论断的一大主要依据是高质量数据不够用了

据最新报道,OpenAI正计划与阿联酋首都阿布扎比的科技公司G42展开一项规模空前的合作计划:在沙漠中建设一个耗电达5千兆瓦的10平方英里数据中心园区。这一规模若实现,将成为全球最大AI基础设施之一。
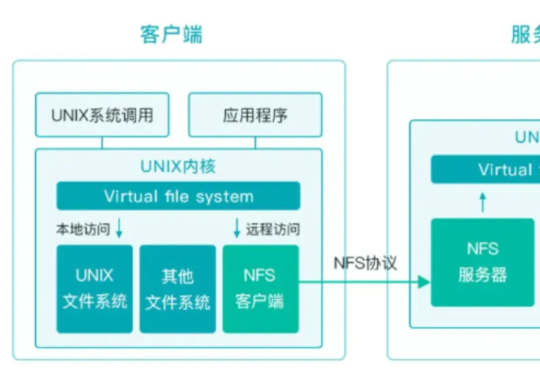
经过对多种开源存储系统的评估对比,我们选择了 JuiceFS 。我们的架构采用 Redis 进行高性能元数据管理,同时构建了自有 MinIO 集群作为底层对象存储,这一架构完美解决了模型训练场景中的数据读写瓶颈、元数据访问延迟以及计算资源之间的存储互通问题。

统一图像理解和生成,还实现了新SOTA。