
编舞人失业!南理工+清华+南大新作:一首歌实现高质量和谐群舞
编舞人失业!南理工+清华+南大新作:一首歌实现高质量和谐群舞当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。
来自主题: AI技术研报
11222 点击 2025-11-27 15:00
 搜索
搜索
当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。

别惊讶,下次给你卖课的健身教练,可能带了个「数字替身」

还记得今年6月罗永浩那场堪比春晚带货专场的直播吗?评论区刷屏、订单秒飘,GMV直接干到了5500万+:

从 AI 女友到数字面试官,人格化 AI 正在「登陆」你的所有屏幕。
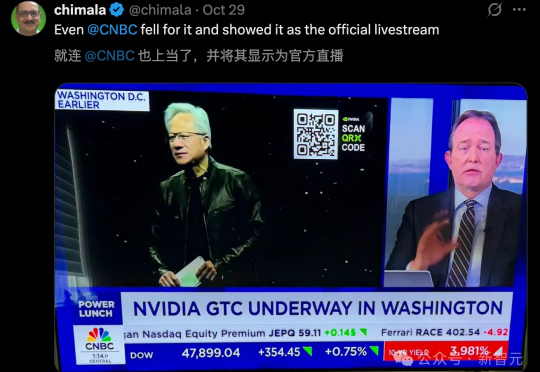
论直播,AI版黄仁勋,竟碾压了本尊?周三的GTC 2025大会上,黄仁勋在华盛顿登台激情演讲。但怪事发生了。另一个打着「NVIDIA LIVE」旗号的直播,却悄悄聚集了近10万观众。

尽管员工每天大部分时间都在项目中进行沟通与协作,但这一努力常因关键人员的缺席而受阻。当掌握重要信息的同事不在岗时——无论是休假还是处于不同时区,团队其他成员往往只能等待对方回复才能推进工作。
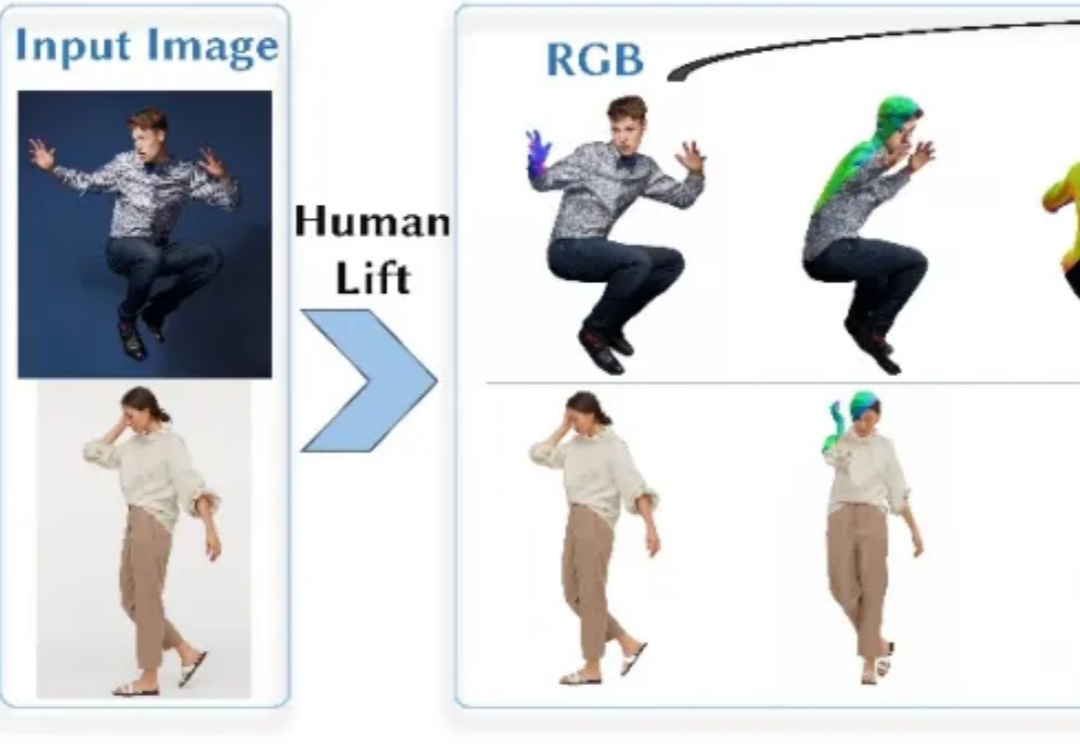
创建具有高度真实感的三维数字人,在三维影视制作、游戏开发以及虚拟/增强现实(VR/AR)等多个领域均有着广泛且重要的应用。

生成式 AI 正在重写 3D 内容的生产流程:从“DCC 工具 + 外包”的线性供给,演进到“资产规模化生成 + 管线可用”的指数供给模式。过去五年,技术范式经历了从实时体积渲染,NeRF,到Score Distillation,3D扩散的快速迭代;需求侧则由游戏与影视,向3D 打印、电商样机、数字人、教育培训、以及AR/VR等长尾场景外溢。

数字人这赛道也越来越卷了, 大模型可以写剧本,语音模型可以配出百变语气,当我越来越不满足于只是把口型对上这件事之后, 那这个只会坐着、不能走路、表情都是提前预设好的、台词数字人,会如何进化?
让数字人的口型随着声音一开一合早已不是新鲜事。更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。