绝对零监督Absolute Zero:类AlphaZero自博弈赋能大模型推理,全新零数据训练范式问世
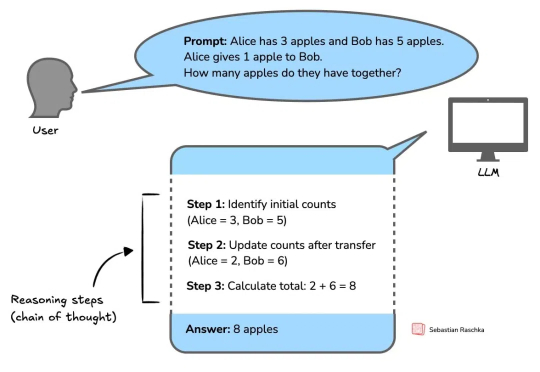
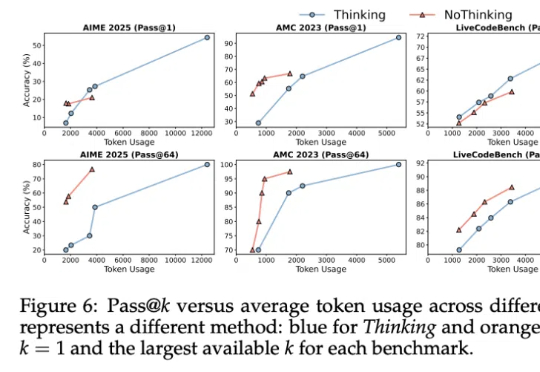
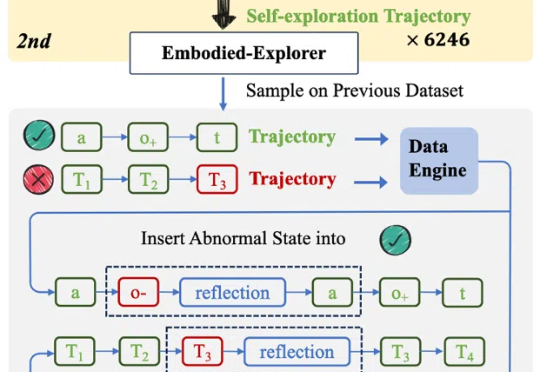
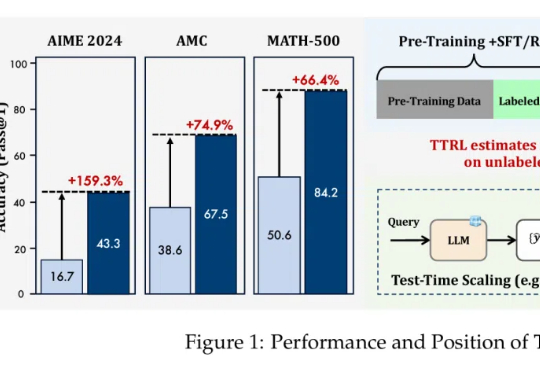
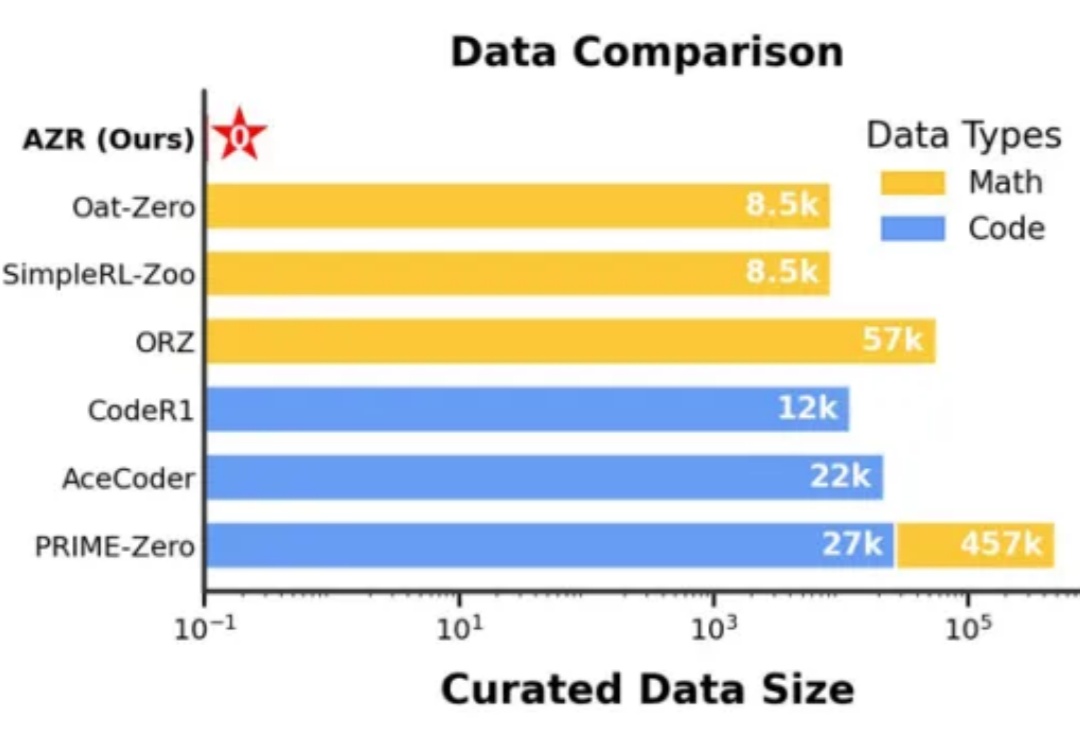
绝对零监督Absolute Zero:类AlphaZero自博弈赋能大模型推理,全新零数据训练范式问世在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。
来自主题: AI技术研报
9322 点击 2025-05-08 14:49