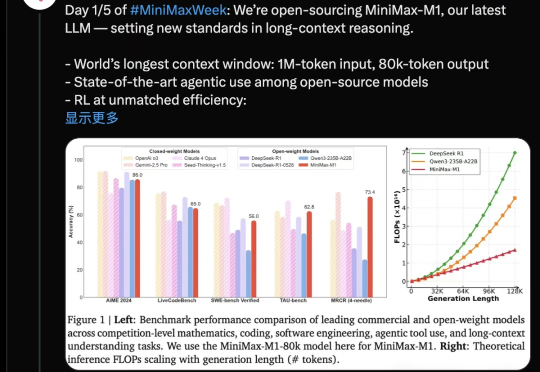
性能比肩DeepSeek-R1,MiniMax仅花380万训出推理大模型性价比新王|开源
性能比肩DeepSeek-R1,MiniMax仅花380万训出推理大模型性价比新王|开源国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。
来自主题: AI技术研报
9087 点击 2025-06-17 11:06
 搜索
搜索
国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。
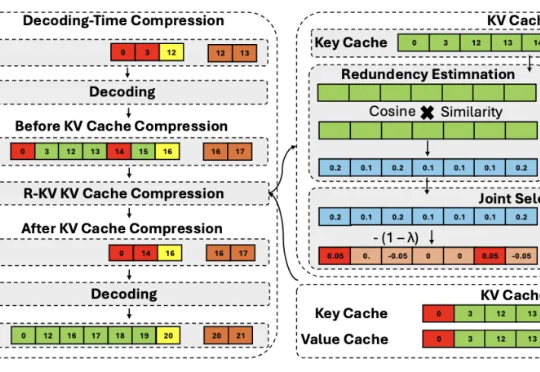
推理大模型虽好,但一个简单的算数问题能推理整整三页,还都是重复的“废话”,找不到重点……
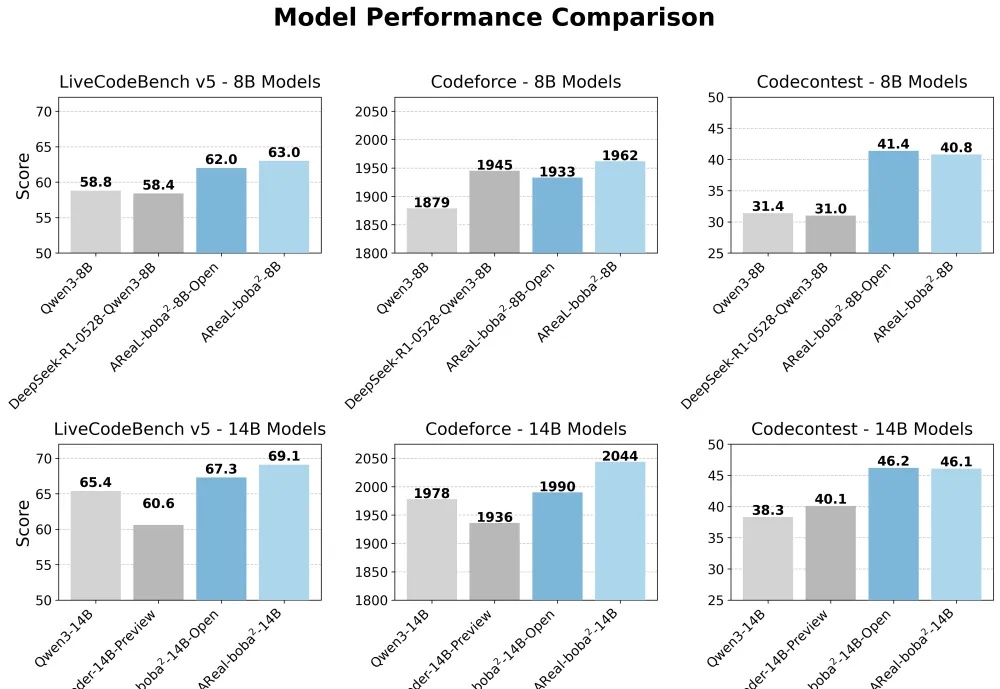
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
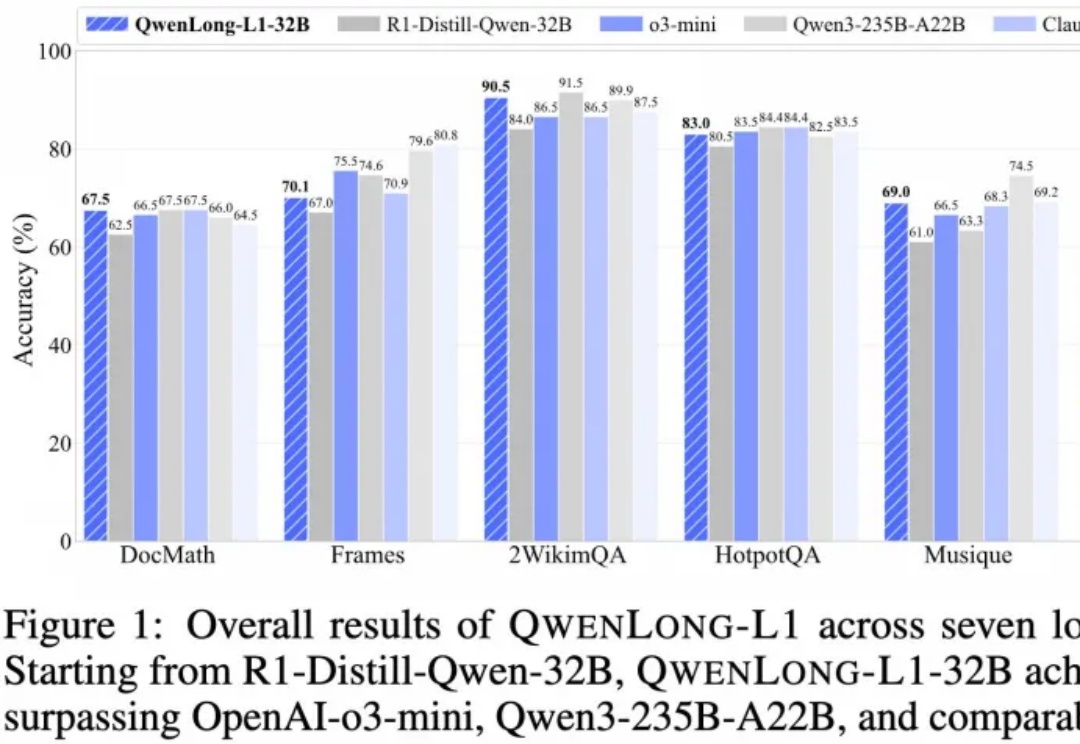
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。
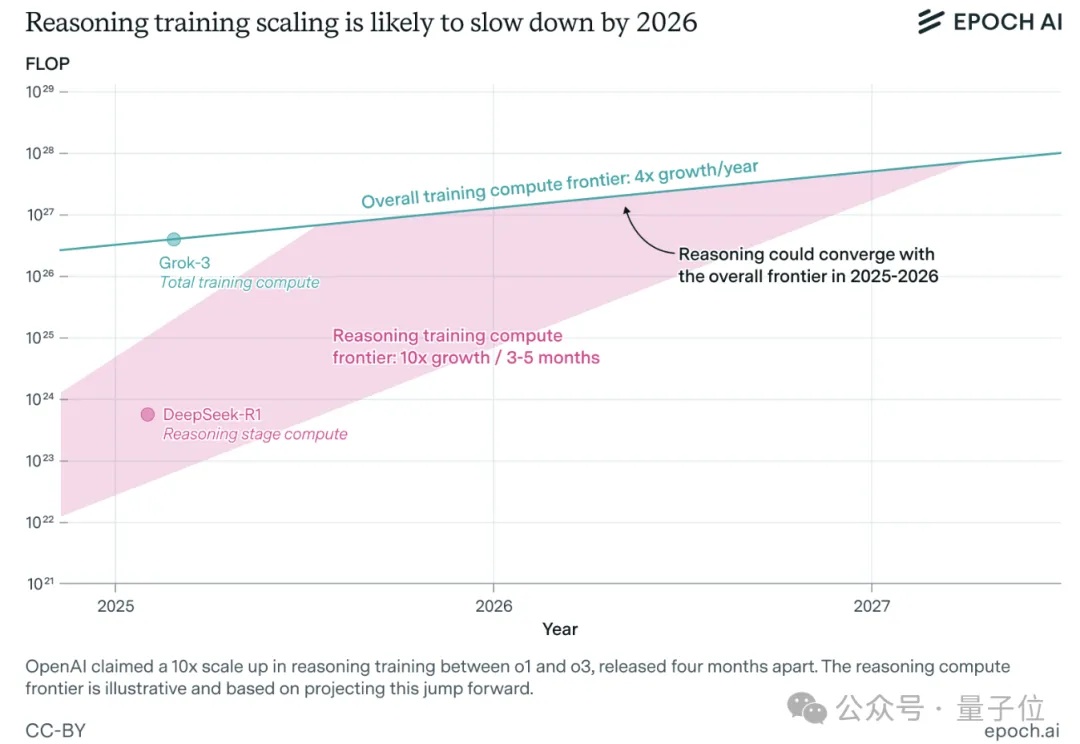
一年之内,大模型推理训练可能就会撞墙。

近日,阿里云通义点金团队与苏州大学携手合作,在金融大语言模型领域推出了突破性的创新成果:DianJin-R1。
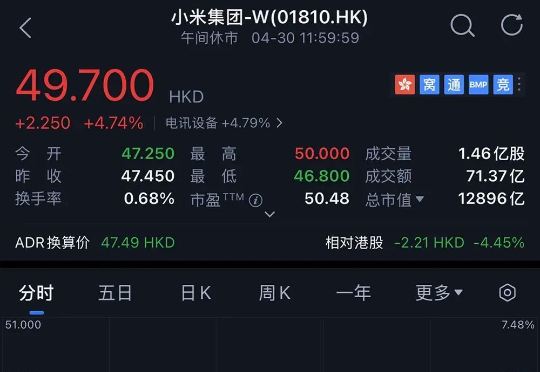
今天上午,小米发布了其首个开源推理大模型-Xiaomi MiMo。通过 25 T 预训练 + MTP 加速 + 规则化 RL + Seamless Rollout,让 7 B 参数的 MiMo-7B 在数理推理和代码生成上赶超 30 B-32 B 大模型,并完整 MIT 开源全系列与工程链,给端-云一体 AI 落地提供了“以小博大”的新范例。
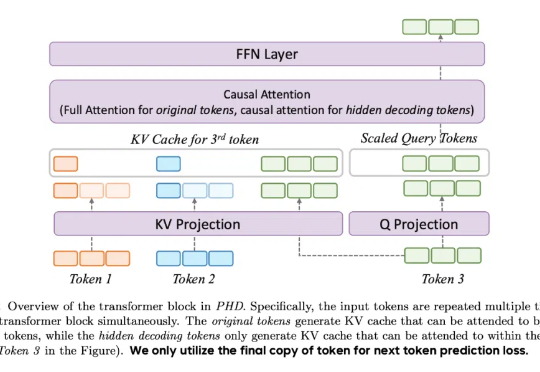
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?