
图像编辑太慢太粗糙?全新开源自回归模型实现精准秒级修改 | 智象未来
图像编辑太慢太粗糙?全新开源自回归模型实现精准秒级修改 | 智象未来AI图像编辑技术发展迅猛,扩散模型凭借强大的生成能力,成为行业主流。 但这类模型在实际应用中始终面临两大难题:一是“牵一发而动全身”,即便只想修改一个细节,系统也可能影响到整个画面;二是生成速度缓慢,难以满足实时交互的需求。
来自主题: AI技术研报
8060 点击 2025-09-03 10:56
 搜索
搜索
AI图像编辑技术发展迅猛,扩散模型凭借强大的生成能力,成为行业主流。 但这类模型在实际应用中始终面临两大难题:一是“牵一发而动全身”,即便只想修改一个细节,系统也可能影响到整个画面;二是生成速度缓慢,难以满足实时交互的需求。
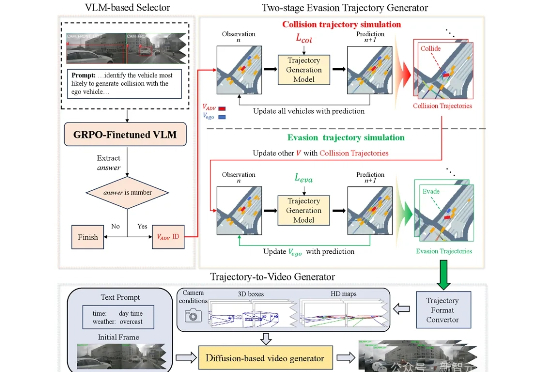
浙江大学与哈工大(深圳)联合推出SafeMVDrive,利用扩散模型结合VLM实现批量化多视角真实域的安全关键视频生成。该方法在保持画质与真实感的同时,显著增强了驾驶场景的危险性。生成的场景用于端到端自动驾驶系统的极限压测,可使得模型的碰撞率提升50倍。

自回归模型,是 AIGC 领域一块迷人的基石。开发者们一直在探索它在视觉生成领域的边界,从经典的离散序列生成,到结合强大扩散模型的混合范式,每一步都凝聚了社区的智慧。
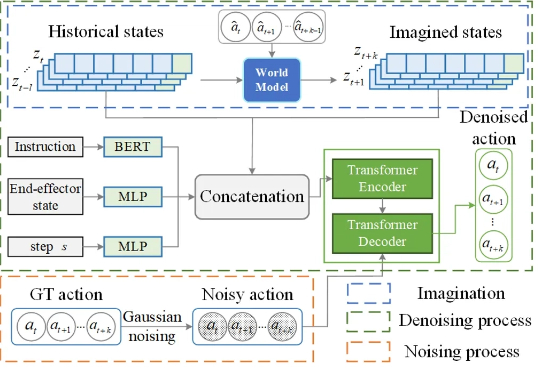
在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。
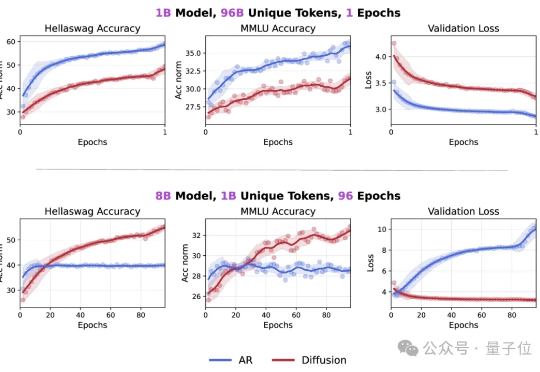
Token危机真的要解除了吗? 最新研究发现,在token数量受限的情况下,扩散语言模型的数据潜力可达自回归模型的三倍多。
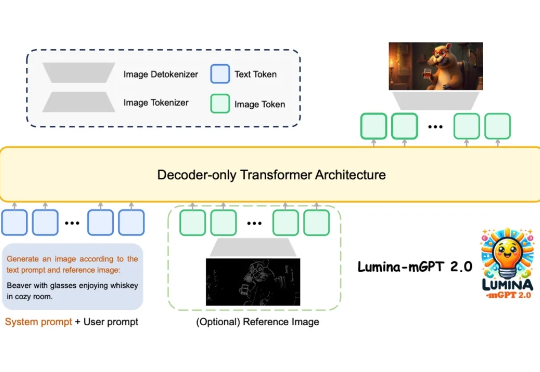
上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。

近年来,扩散模型在图像与视频合成领域展现出前所未有的生成能力,为人脸生成与编辑技术按下了加速键。特别是一张静态人脸驱动任意表情、姿态乃至光照的梦想,正在走向大众工具箱,并在三大场景展现巨大潜力

扩散语言模型(DLMs)是超强的数据学习者。 token 危机终于要不存在了吗? 近日,新加坡国立大学 AI 研究者 Jinjie Ni 及其团队向着解决 token 危机迈出了关键一步。
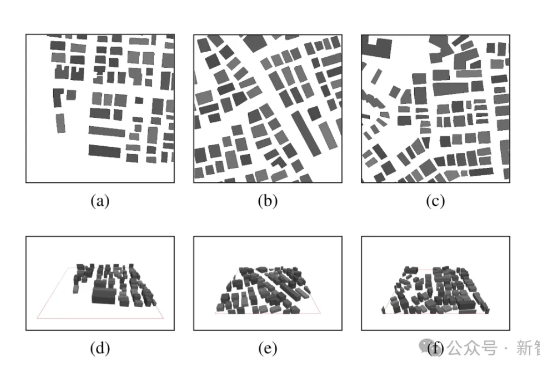
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
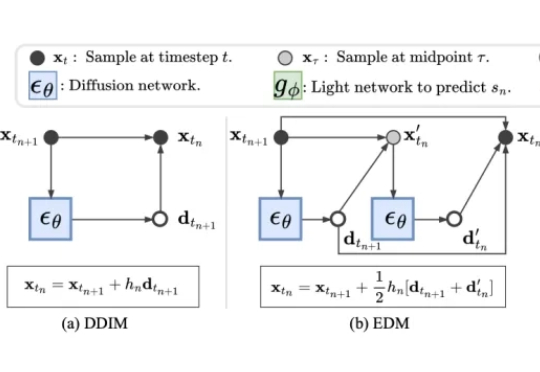
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。