SIGGRAPH2024|上科大、影眸联合提出DressCode:从文本生成3D服装板片
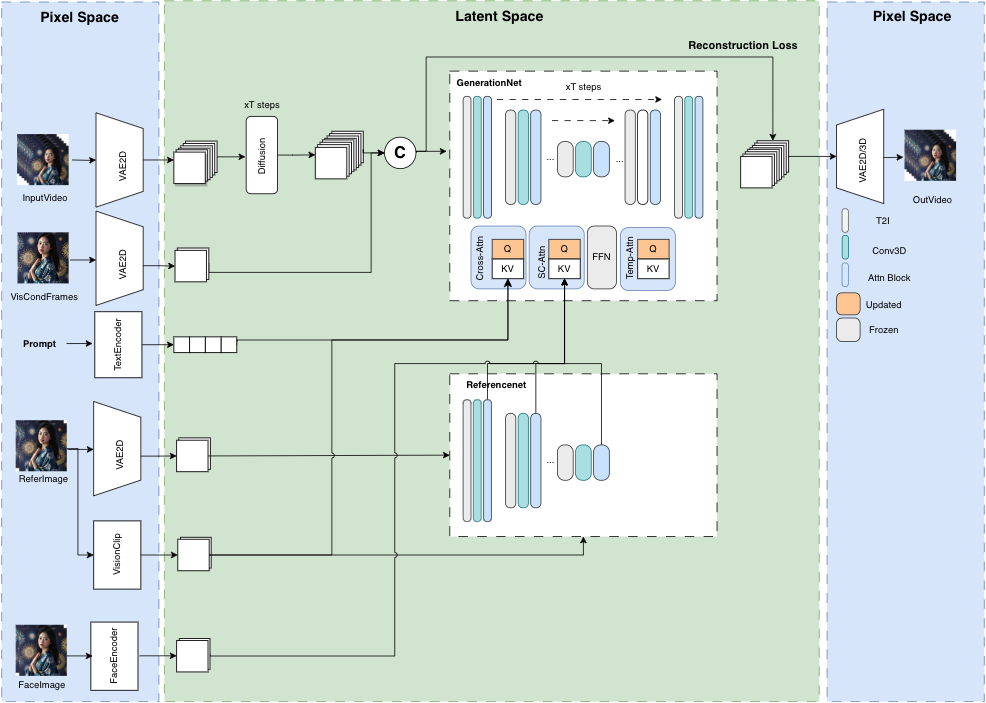
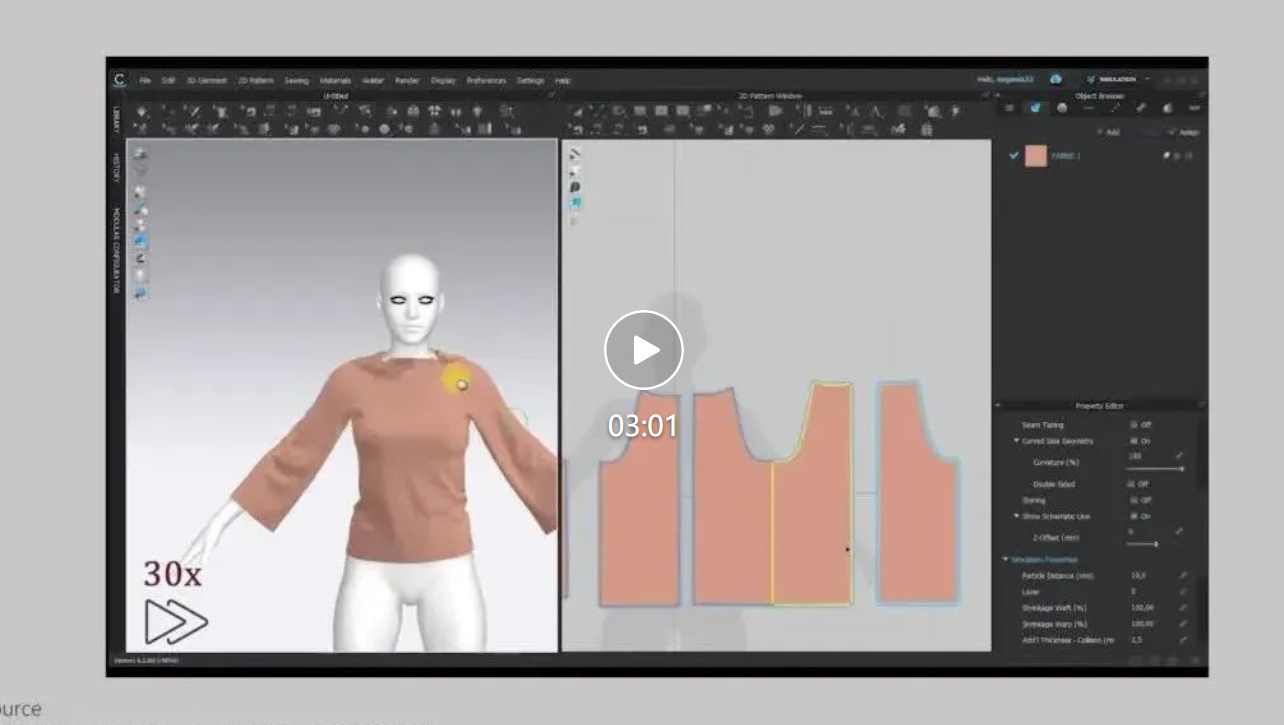
SIGGRAPH2024|上科大、影眸联合提出DressCode:从文本生成3D服装板片3D生成是生成式人工智能和计算机图形学领域最引人注目的话题之一,符合影视、游戏标准的3D生成尤其受产业界关注。在生产流程中,一般品类的3D资产往往通过手工建模或者扫描的方式制作。但作为3D资产的一个重要类别,服装资产的往往来源于平面板片与物理模拟等流程,而不是直接在3D上建模。
来自主题: AI技术研报
8609 点击 2024-06-15 15:44