扩散模型训练方法一直错了!谢赛宁:Representation matters
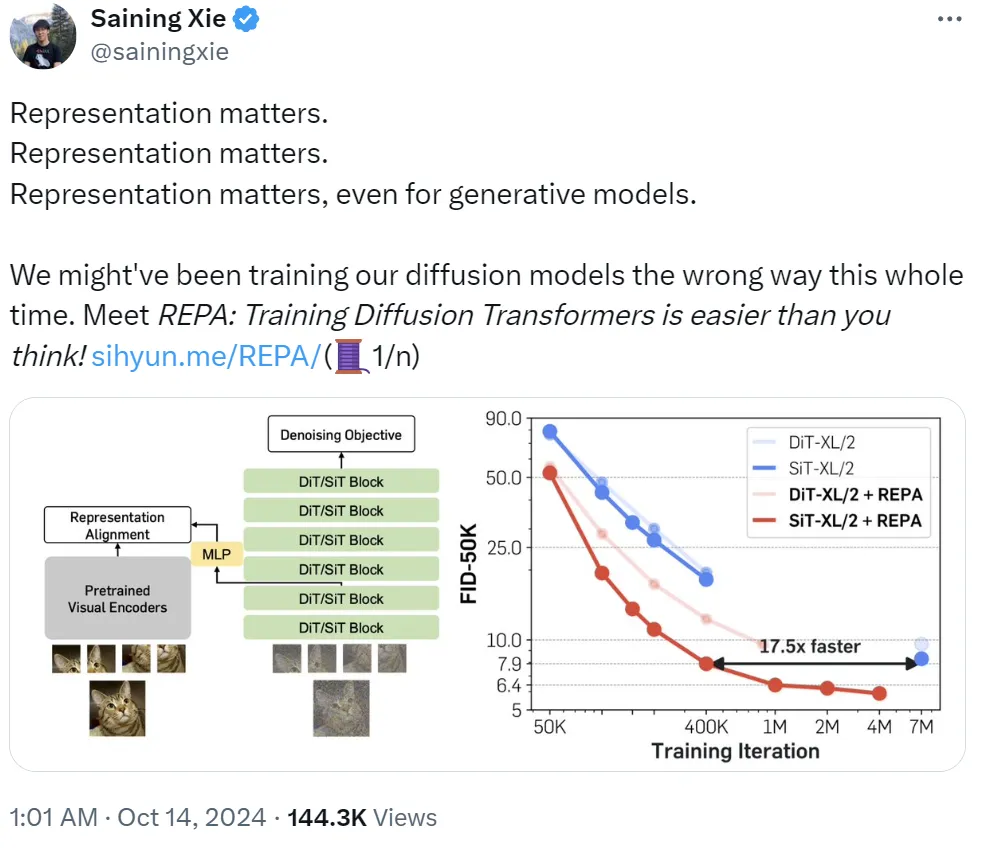
扩散模型训练方法一直错了!谢赛宁:Representation matters是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」
来自主题: AI技术研报
5441 点击 2024-10-14 15:22