
斯坦福吴佳俊扩散自蒸馏来了!突破文生图身份保留挑战
斯坦福吴佳俊扩散自蒸馏来了!突破文生图身份保留挑战近年来,文本到图像扩散模型为图像合成树立了新标准,现在模型可根据文本提示生成高质量、多样化的图像。然而,尽管这些模型从文本生成图像的效果令人印象深刻,但它们往往无法提供精确的控制、可编辑性和一致性 —— 而这些特性对于实际应用至关重要。
来自主题: AI技术研报
8475 点击 2024-11-29 15:23
 搜索
搜索
近年来,文本到图像扩散模型为图像合成树立了新标准,现在模型可根据文本提示生成高质量、多样化的图像。然而,尽管这些模型从文本生成图像的效果令人印象深刻,但它们往往无法提供精确的控制、可编辑性和一致性 —— 而这些特性对于实际应用至关重要。

自回归方法,在图像生成中观察到了 Scaling Law。 「Scaling Law 撞墙了?」这恐怕是 AI 社区最近讨论热度最高的话题。

扩散模型的本质竟是进化算法!生物学大佬从数学的角度证实了这个结论,并结合扩散模型创建了全新的进化算法。

DIAMOND是一种新型的强化学习智能体,在一个由扩散模型构建的虚拟世界中进行训练,能够以更高效率学习和掌握各种任务。在Atari 100k基准测试中,DIAMOND的平均得分超越了人类玩家,证明了其在模拟复杂环境中处理细节和进行决策的能力。

Sora 的发布让广大研究者及开发者深刻认识到基于 Transformer 架构扩散模型的巨大潜力。作为这一类的代表性工作,DiT 模型抛弃了传统的 U-Net 扩散架构,转而使用直筒型去噪模型。鉴于直筒型 DiT 在隐空间生成任务上效果出众,后续的一些工作如 PixArt、SD3 等等也都不约而同地使用了直筒型架构。

第8届CoRL于2024年11月6日至9日在德国慕尼黑举行,展示了机器人学习领域的前沿研究和发展,尤其是在自主系统、机器人控制和多模态人工智能领域。
【新智元导读】刚刚,一款专为消费级显卡设计的全新非自回归掩码图像建模的文本到图像生成模型——Meissonic发布,标志着图像生成即将进入「端侧时代」。
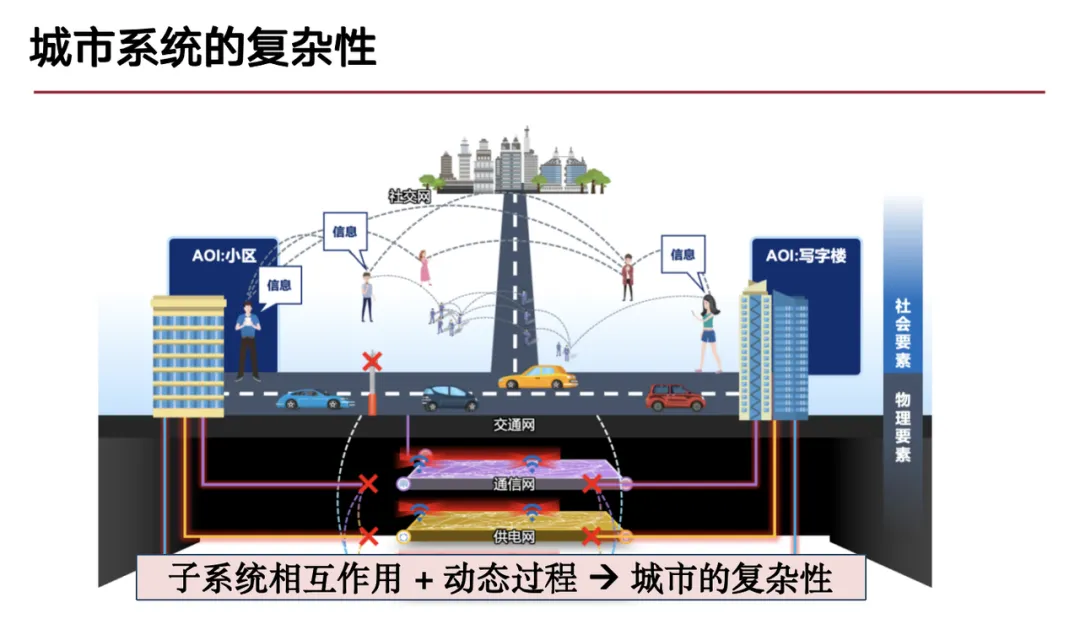
在 HyperAI超神经联合出品的 COSCon’24 AI for Science 论坛中,来自清华大学电子工程系城市科学与计算研究中心的博士后研究员丁璟韬带来了深度分享,以下为演讲精华实录。

VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能通过选择最佳候选图像来实际改善生成的图像。

Bifröst 是一个创新的3D感知图像合成框架,它利用扩散模型来执行基于语言指令的图像合成任务。