
具身大模型LaST₀:双臂/移动/灵巧手全面新SOTA,首次引入隐空间时空思维链
具身大模型LaST₀:双臂/移动/灵巧手全面新SOTA,首次引入隐空间时空思维链LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混
来自主题: AI技术研报
7059 点击 2026-02-08 11:50
 搜索
搜索
LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混

什么样的思维链,能「教会」学生更好地推理?
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。

1月10日,在蓝驰创投举办的第五期不鸣创业营中,Kimi总裁张予彤分享了在AI浪潮奔涌的当下,创业者如何思考决策,以及如何应对各种波动与变化。
不讲武德!游戏圈这回真是被AI抄家了。(doge)
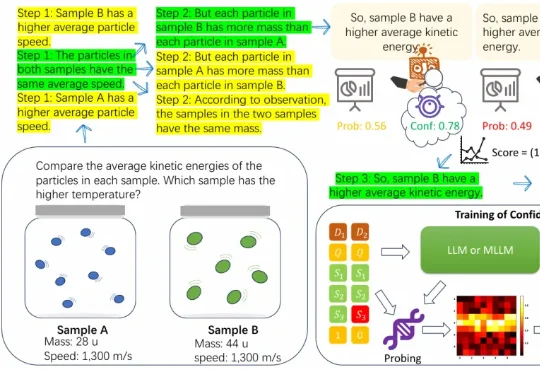
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
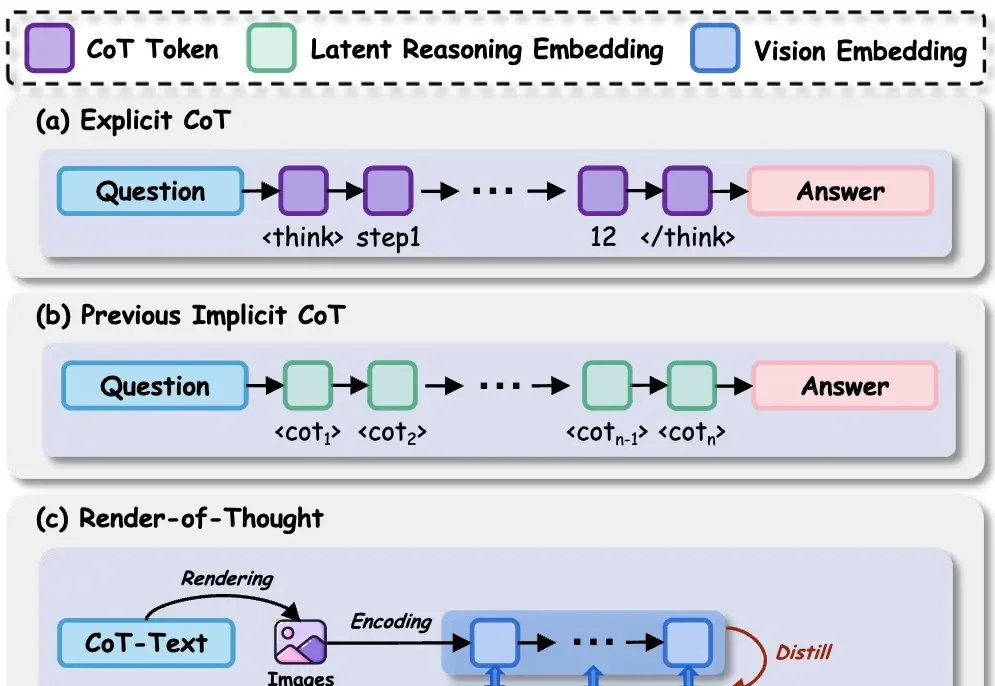
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
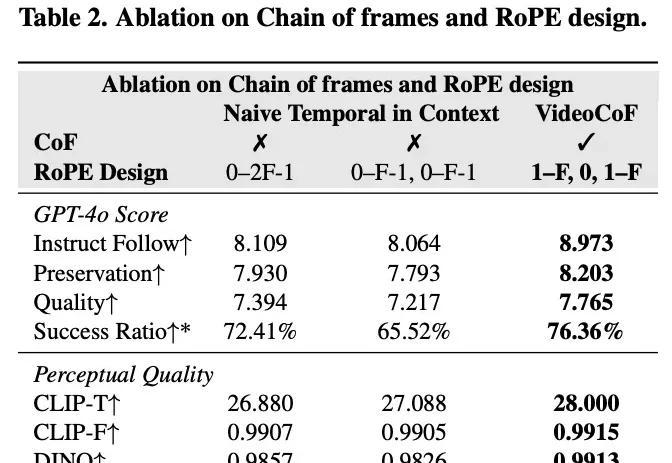
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
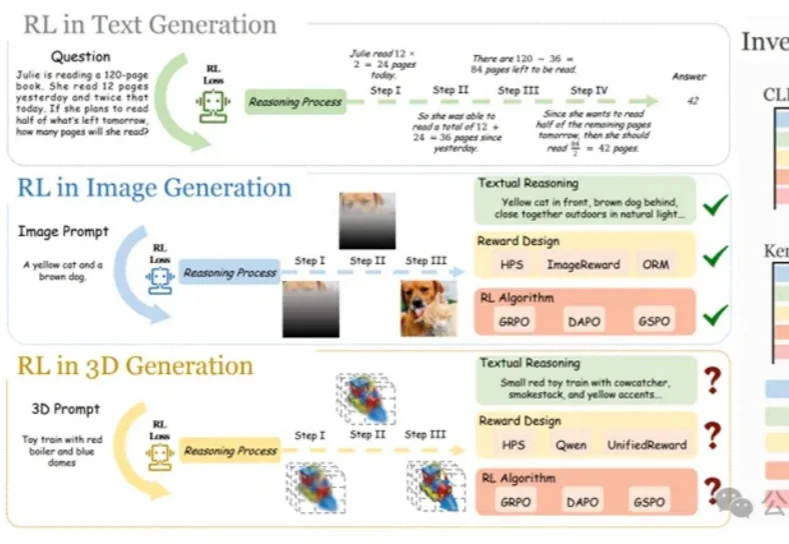
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

DeepSeek V3.2的Agentic能力大增,离不开这项关键机制:Interleaved Thinking(交错思维链)。Interleaved Thinking风靡开源社区背后,离不开另一家中国公司的推动。