
思维链监督和强化的图表推理,7B模型媲美闭源大尺寸模型
思维链监督和强化的图表推理,7B模型媲美闭源大尺寸模型近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
来自主题: AI技术研报
9171 点击 2025-08-01 16:08
 搜索
搜索
近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
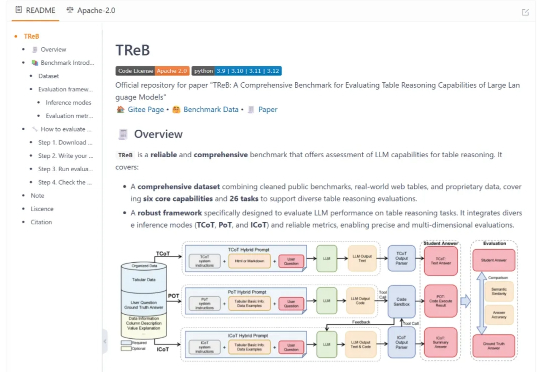
7 月 26 日,在 WAIC 2025 世界人工智能大会上,中国移动九天人工智能研究院全面开源九天结构化数据大模型 “数据 - 模型 - 测评” 三位一体的完整模型体系,包括了结构化数据体系、TReB 标准化测评框架、支持微调及推理全流程模型。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
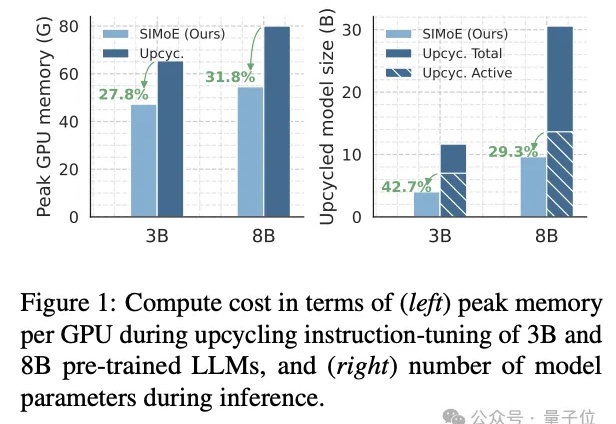
只需一次指令微调,即可让普通大模型变身“全能专家天团”?
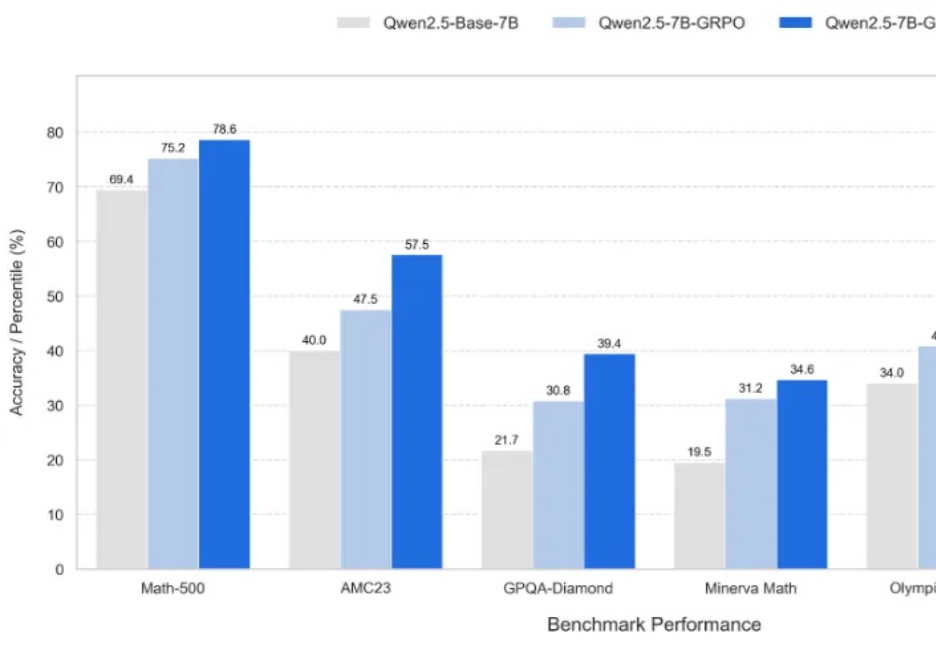
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
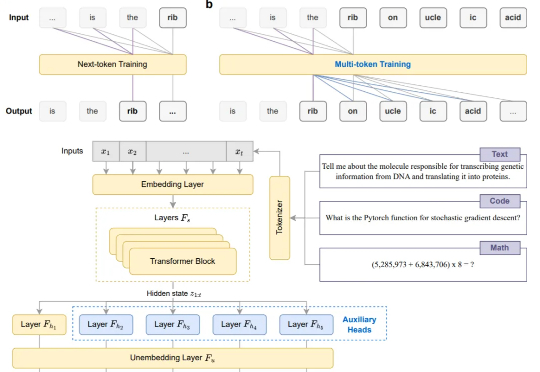
告别Next-token,现在模型微调阶段就能直接多token预测!
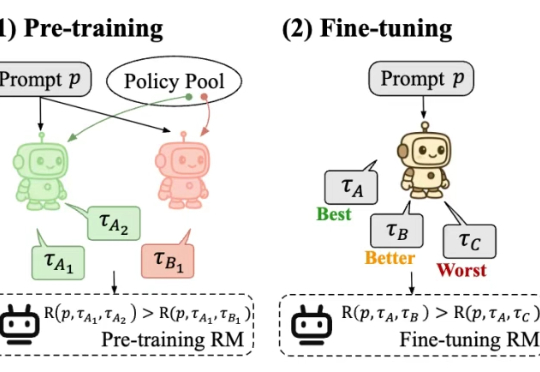
最近,一款全新的奖励模型「POLAR」横空出世。它开创性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注的依赖,更展现出强大的Scaling潜力,让小模型也能超越规模大数十倍的对手。

MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
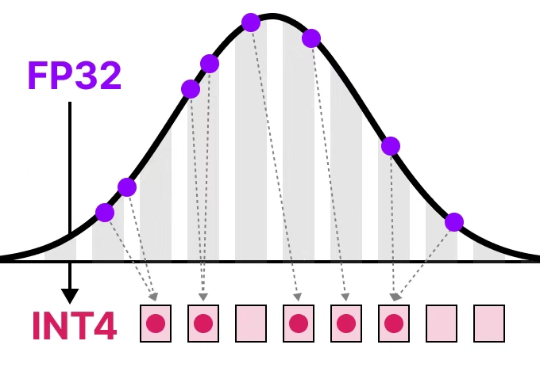
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。