
比LoRA更高效!上交大&哈佛推出新微调框架,瞄准特定任务方向
比LoRA更高效!上交大&哈佛推出新微调框架,瞄准特定任务方向比LoRA更高效的模型微调方法来了——
来自主题: AI技术研报
10309 点击 2024-09-16 21:35
 搜索
搜索
比LoRA更高效的模型微调方法来了——
微调的所有门道,都在这里了。

OpenAI推出GPT-4o模型微调功能。

一觉醒来,OpenAI又上新功能了:

合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。

席卷开源界的AI生图王者诞生了!发布半个月,Flux已经成为替代Midjourney的宠儿。各路开发者们开始用自己的照片微调LoRA,一人拿捏多种风格。

互相检查,让小模型也能解决大问题。

发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。

智谱AI把自研打造的大模型给开源了。
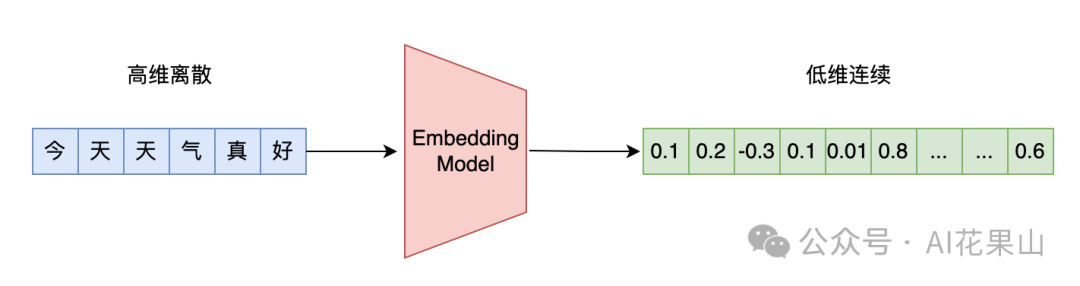
在本篇文章中,笔者将讨论以下几个问题: • 向量模型在 RAG 系统中的作用 有哪些性能不错的向量模型(从 RAG 角度) 不同向量模型的评测基准 MTEB 业务中选择向量模型有哪些考量 如何 Finetune 向量模型