模型调优无需标注数据!将Llama 3.3 70B直接提升到GPT-4o水平
模型调优无需标注数据!将Llama 3.3 70B直接提升到GPT-4o水平最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
来自主题: AI技术研报
9605 点击 2025-03-30 14:33
 搜索
搜索
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?
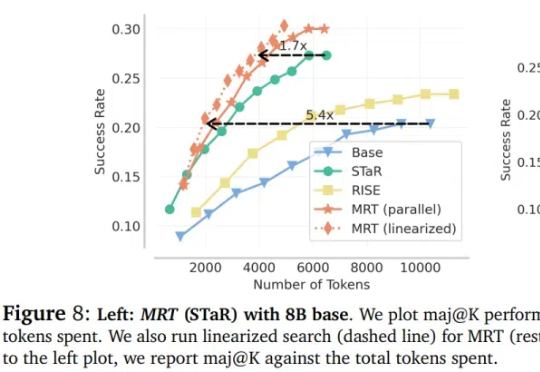
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

只要微调模型生成的前8-32个词,就能让大模型推理能力达到和传统监督训练一样的水平?

开源微调神器Unsloth带着黑科技又来了:短短两周后,再次优化DeepSeek-R1同款GRPO训练算法,上下文变长10倍,而显存只需原来的1/10!

微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。
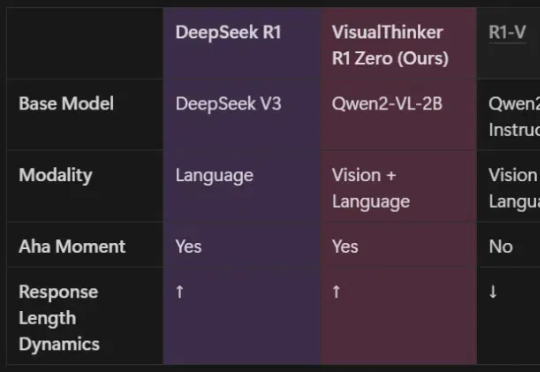
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!
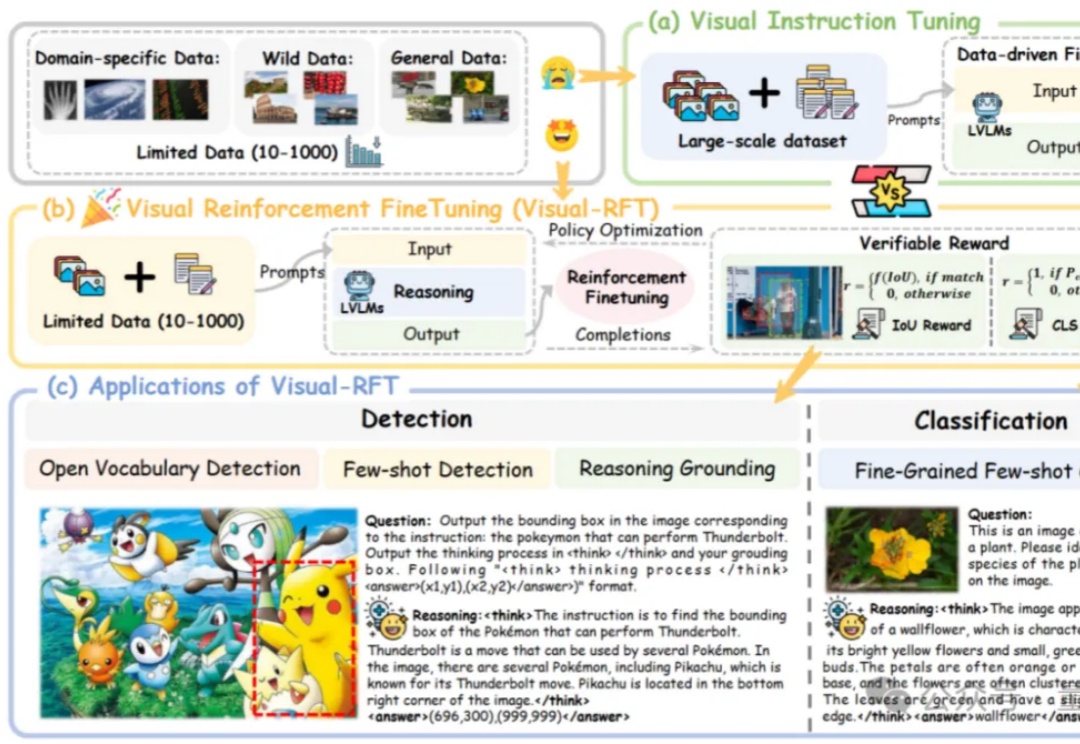
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!