只用512张H200!106B模型靠分布式RL杀出重围,全网开源
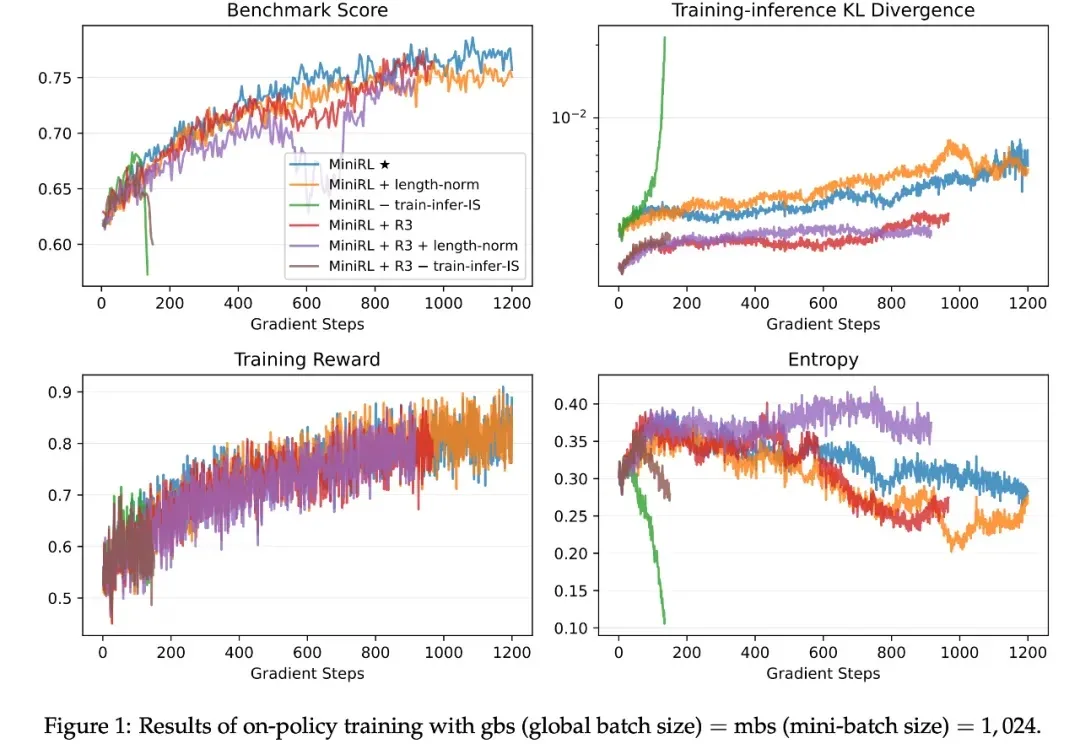
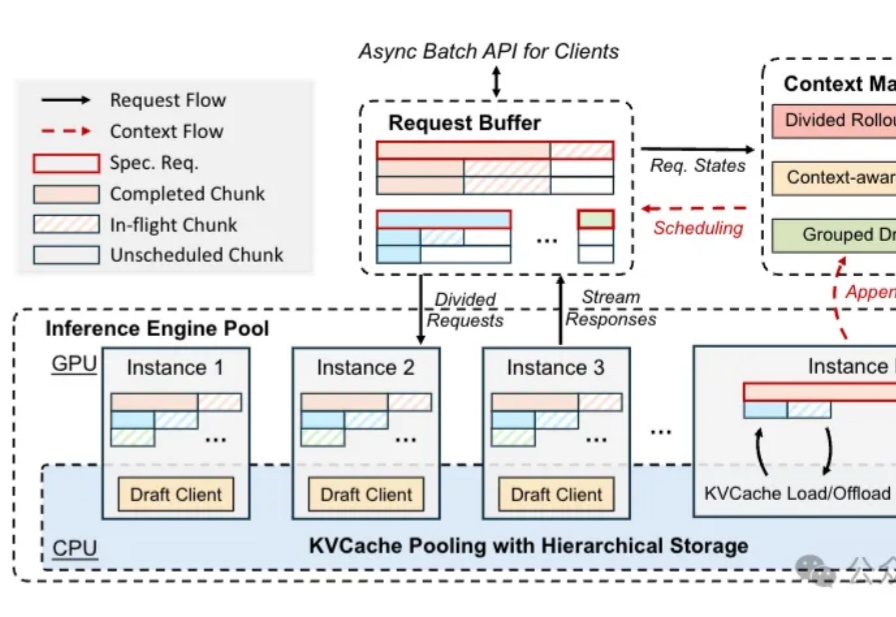
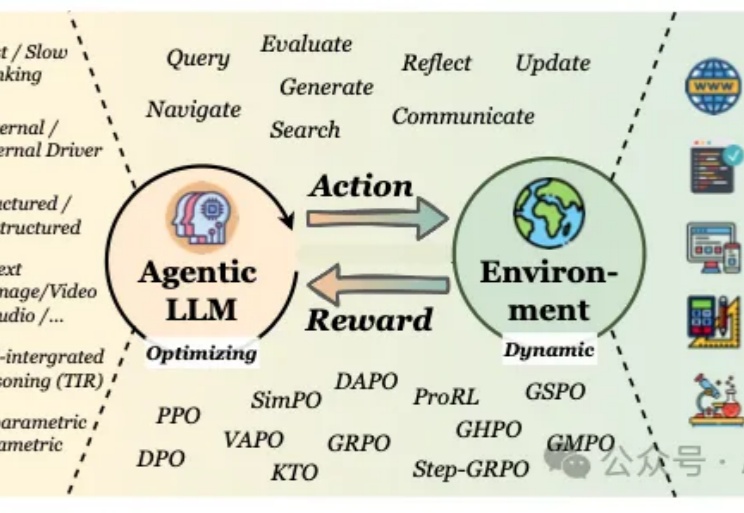
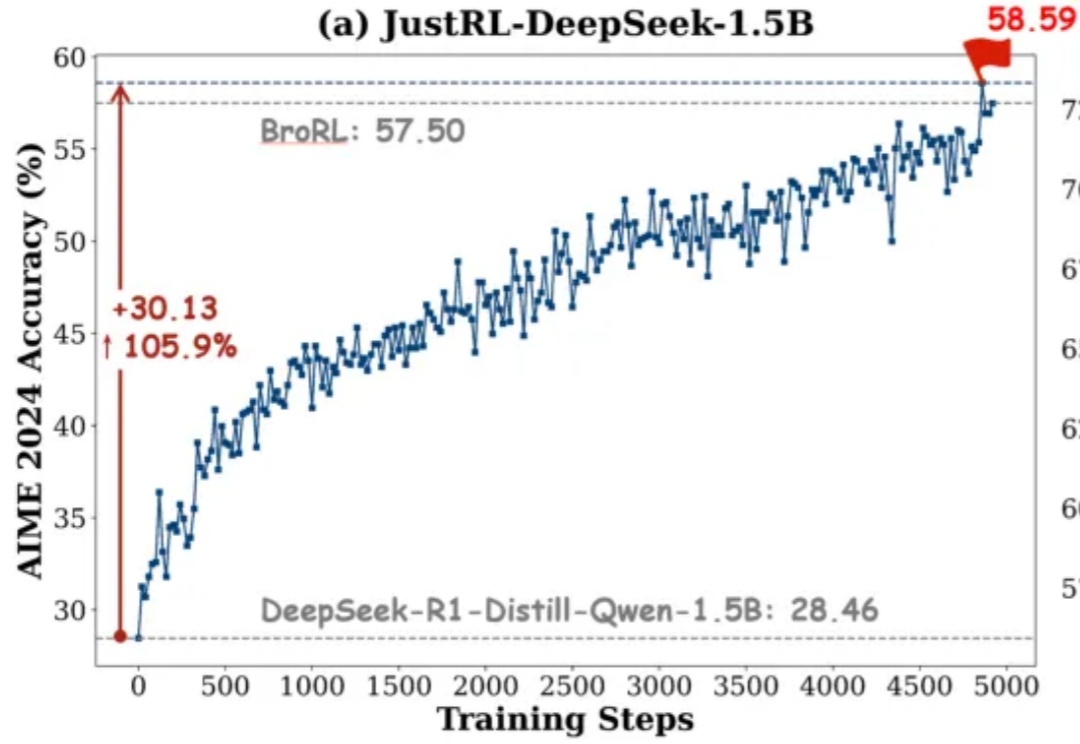
只用512张H200!106B模型靠分布式RL杀出重围,全网开源最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
来自主题: AI资讯
9661 点击 2025-12-10 16:14