给GRPO加上运筹外挂让7B模型比肩GPT-4!Li Auto团队发布多目标强化学习新框架 | ICASSP 2026
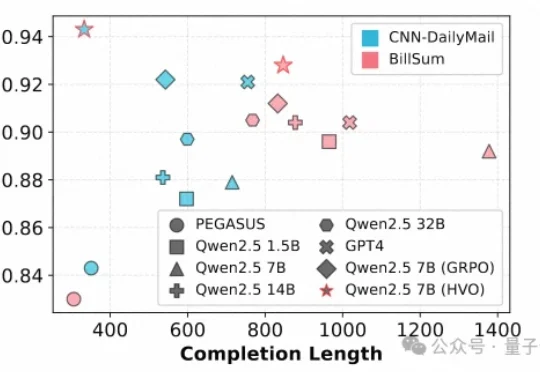
给GRPO加上运筹外挂让7B模型比肩GPT-4!Li Auto团队发布多目标强化学习新框架 | ICASSP 2026文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
来自主题: AI技术研报
9749 点击 2026-02-10 14:11