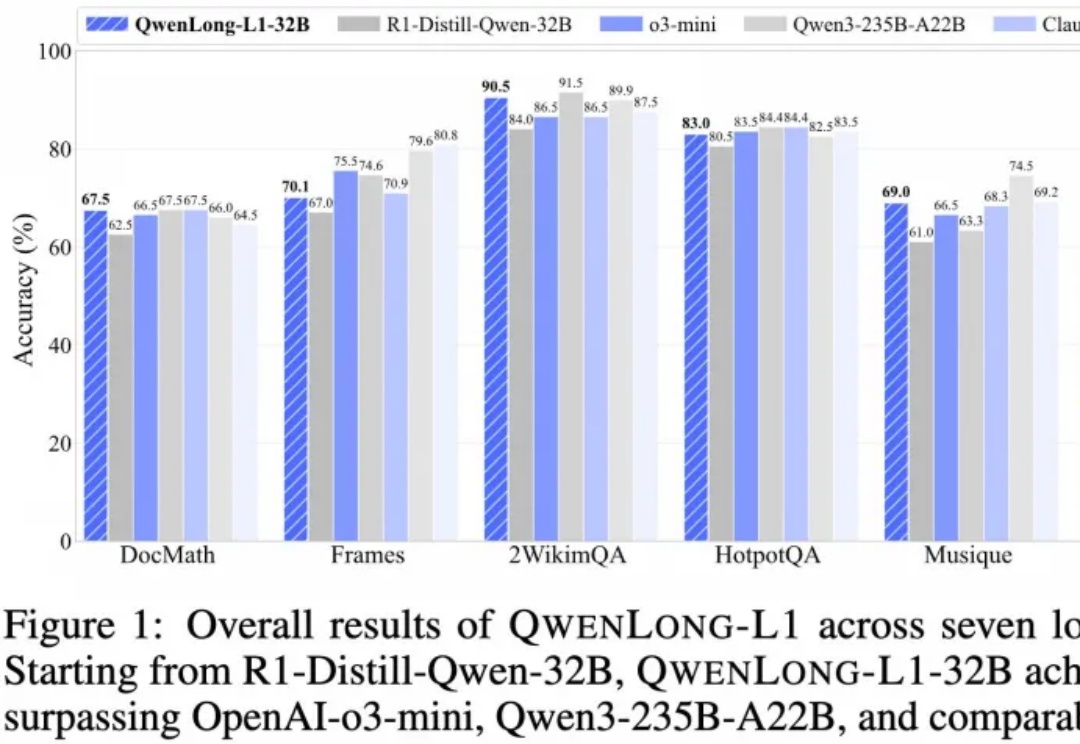
阿里开源长文本深度思考模型!渐进式强化学习破解长文本训练难题,登HuggingFace热榜
阿里开源长文本深度思考模型!渐进式强化学习破解长文本训练难题,登HuggingFace热榜推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。
来自主题: AI技术研报
8545 点击 2025-05-27 16:58
 搜索
搜索
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。

近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。
别人都在用 X 发帖子,分享新鲜事物,微软副总裁 Nando de Freitas 却有自己的想法:他要在 X 上「开课」,发布一些关于人工智能教育的帖子。该系列会从 LLM 的强化学习开始,然后逐步讲解扩散、流匹配,以及看看这些技术接下来会如何发展。
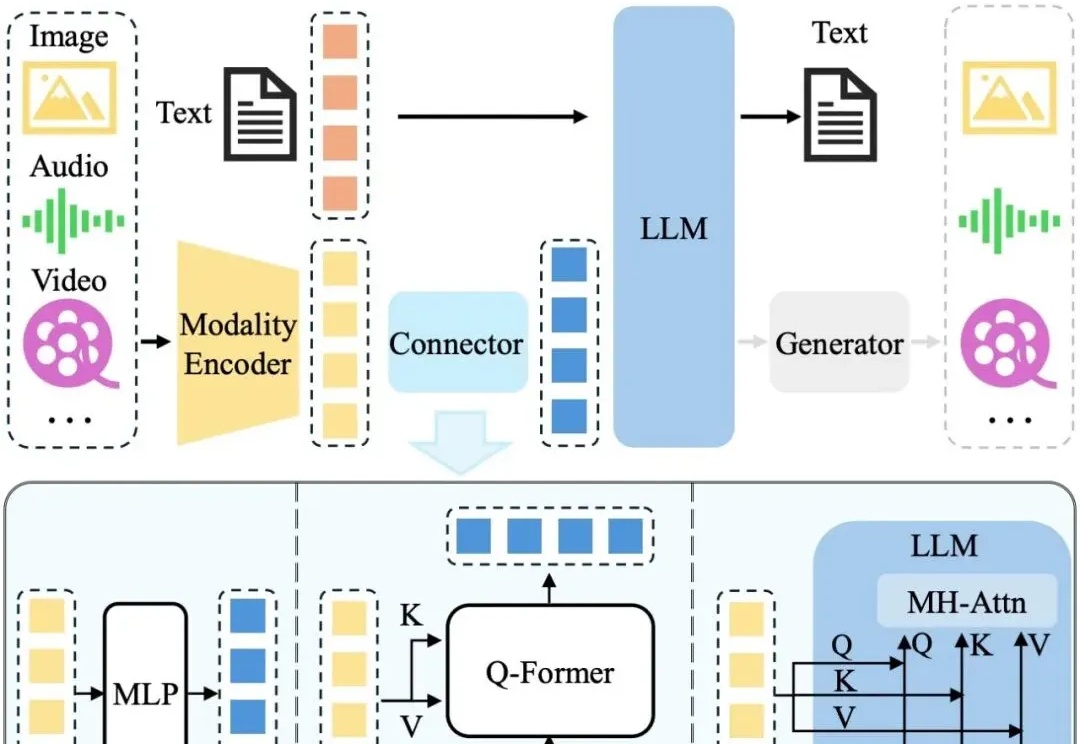
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。
自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。

我们发现,当模型在测试阶段花更多时间思考时,其推理表现会显著提升,这打破了业界普遍依赖预训练算力的传统认知。
强化学习(RL)+真实搜索引擎,可以有效提升大模型检索-推理能力。

近日,腾讯 PCG 社交线的研究团队针对这一问题,采用强化学习(RL)训练方法,通过分组相对策略优化(Group Relative Policy Optimization, GRPO)算法,结合基于奖励的课程采样策略(Reward-based Curriculum Sampling, RCS),将其创新性地应用在意图识别任务上,

R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。

近日,《自然》杂志独家专访了OpenAI首席科学家Jakub Pachocki,他揭示了推理模型、强化学习如何赋予AI自主发现科学的能力,并分享了AI如何在五年内重塑科学研究与经济格局的雄心。