为什么用错奖励,模型也能提分?新研究:模型学的不是新知识,是思维
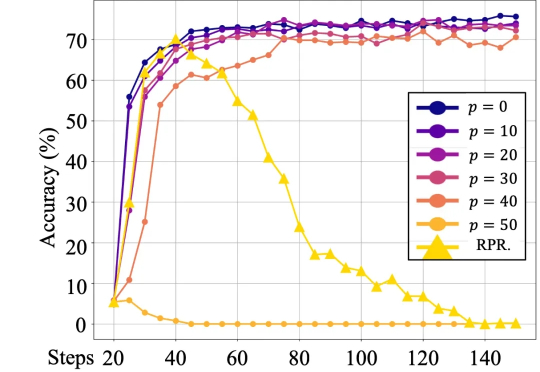
为什么用错奖励,模型也能提分?新研究:模型学的不是新知识,是思维最近的一篇论文中,来自人大和腾讯的研究者们的研究表明,语言模型对强化学习中的奖励噪音具有鲁棒性,即使翻转相当一部分的奖励(例如,正确答案得 0 分,错误答案得 1 分),也不会显著影响下游任务的表现。
来自主题: AI技术研报
8442 点击 2025-06-08 14:35
 搜索
搜索
最近的一篇论文中,来自人大和腾讯的研究者们的研究表明,语言模型对强化学习中的奖励噪音具有鲁棒性,即使翻转相当一部分的奖励(例如,正确答案得 0 分,错误答案得 1 分),也不会显著影响下游任务的表现。
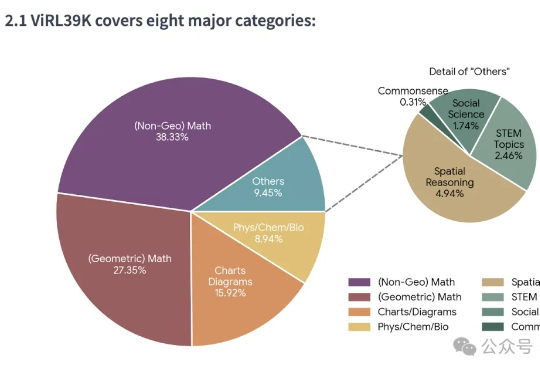
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck
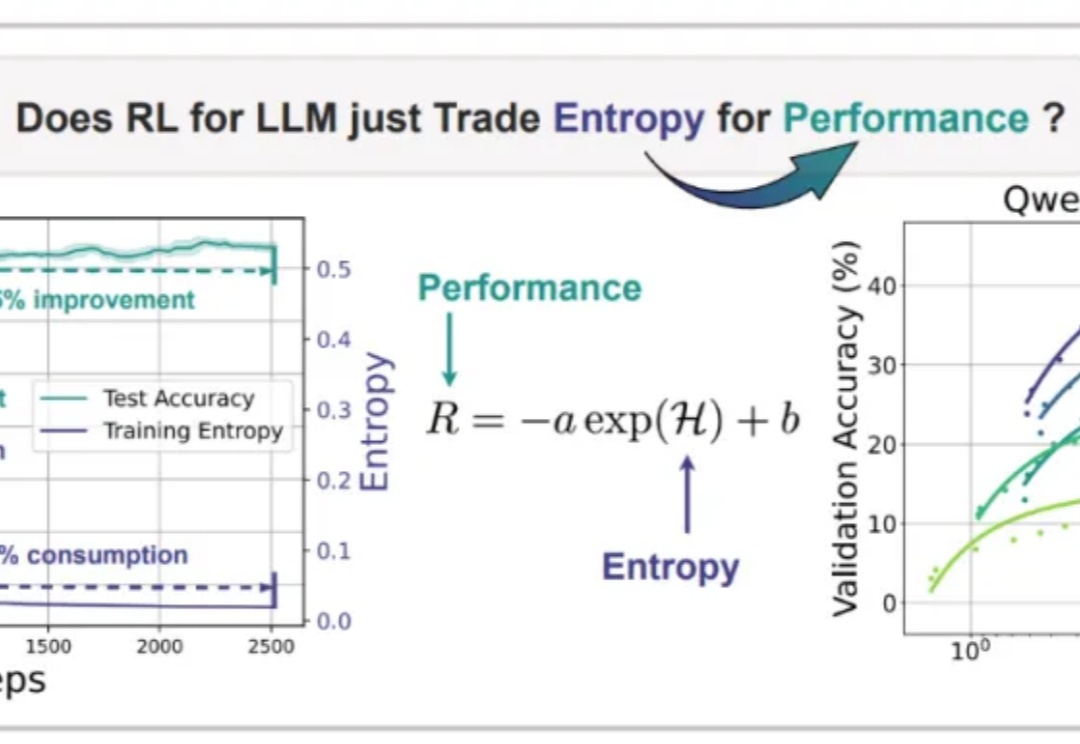
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。

清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!

无监督的熵最小化(EM)方法仅需一条未标注数据和约10步优化,就能显著提升大模型在推理任务上的表现,甚至超越依赖大量数据和复杂奖励机制的强化学习(RL)。EM通过优化模型的预测分布,增强其对正确答案的置信度,为大模型后训练提供了一种更高效简洁的新思路。
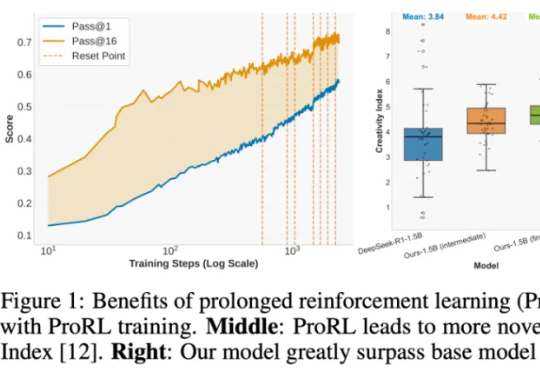
强化学习(RL)到底是语言模型能力进化的「发动机」,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?
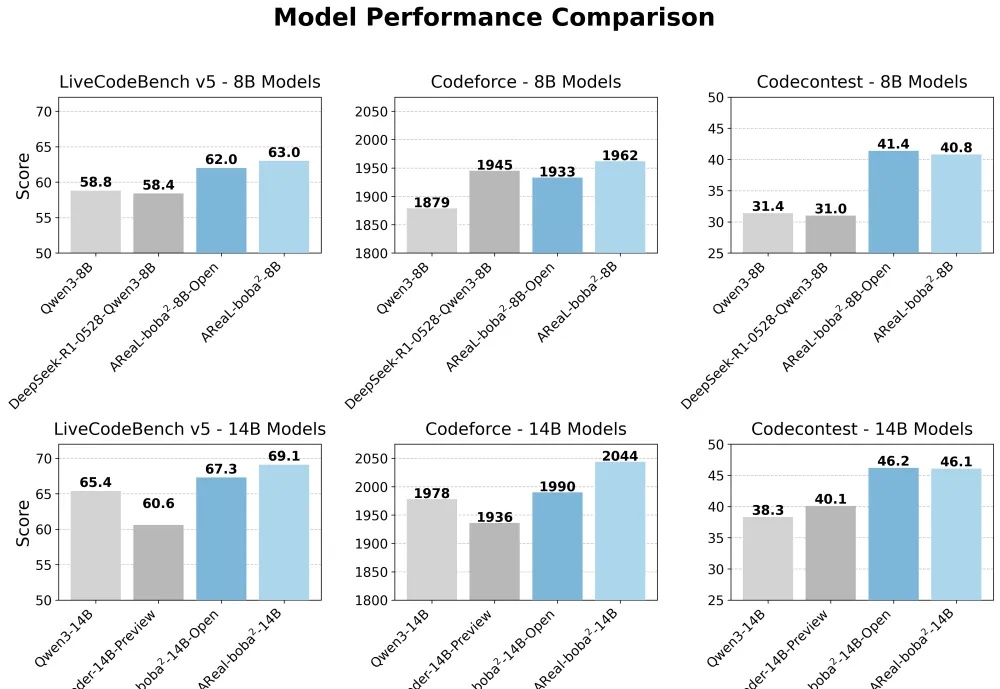
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
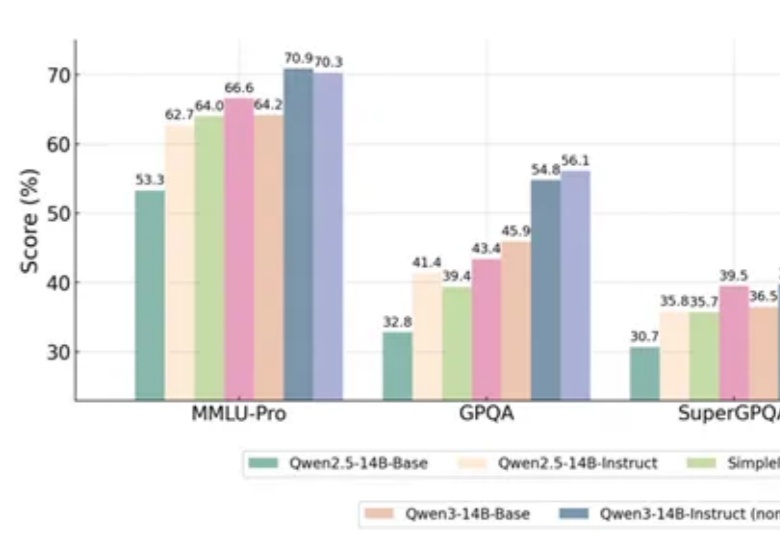
一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!
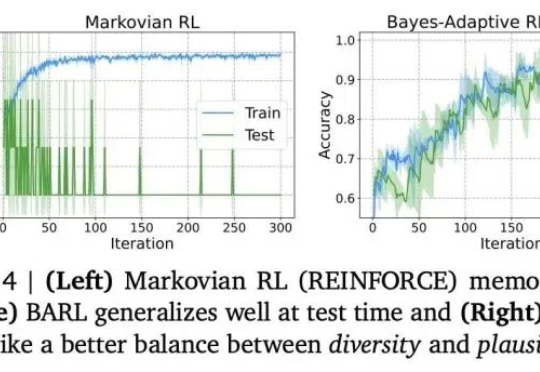
推理模型常常表现出类似自我反思的行为,但问题是——这些行为是否真的能有效探索新策略呢?