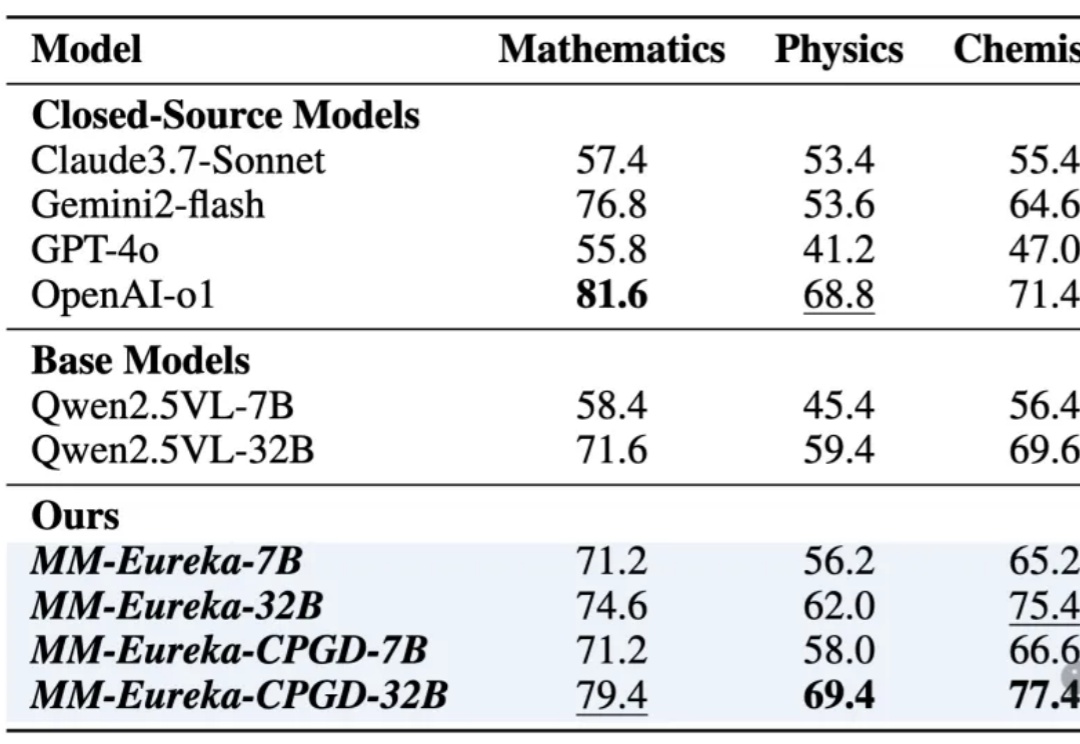
只训练数学,却在物理化学生物战胜o1!新强化学习算法带来显著性能提升,还缓解训练崩溃问题
只训练数学,却在物理化学生物战胜o1!新强化学习算法带来显著性能提升,还缓解训练崩溃问题只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
来自主题: AI技术研报
9698 点击 2025-06-23 14:29
 搜索
搜索
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
只靠强化学习,AGI就能实现?Claude-4核心成员放话「5年内AI干掉白领」,却被Karpathy等联手泼冷水!持续学习真的可能吗?RL的真正边界、下一代智能的关键转折点到底在哪儿?
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。
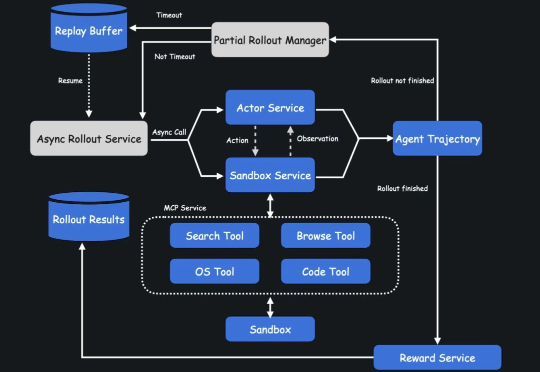
这款 Agent 擅长多轮搜索和推理,平均每项任务执行 23 个推理步骤,访问超过 200 个网址。它是基于 Kimi k 系列模型的内部版本构建,并完全通过端到端智能体强化学习进行训练,也是国内少有的基于自研模型打造的 Agent。

随着语言模型在强化学习和 agentic 领域的进步,agent 正在从通用领域快速渗透到垂直领域,科学和生物医药这类高价值领域尤其受到关注。
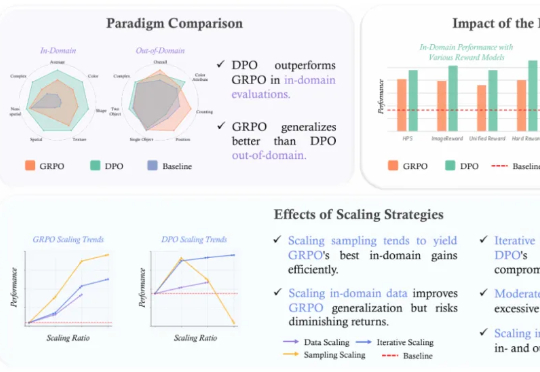
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。

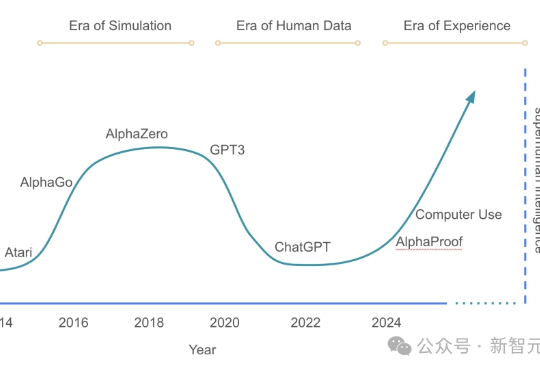
AI迈入经验时代,2025 年 6 月 6 日,第七届北京智源大会在北京正式开幕,强化学习奠基人、2025年图灵奖得主、加拿大计算机科学家Richard S. Sutton以“欢迎来到经验时代”为题发表主旨演讲
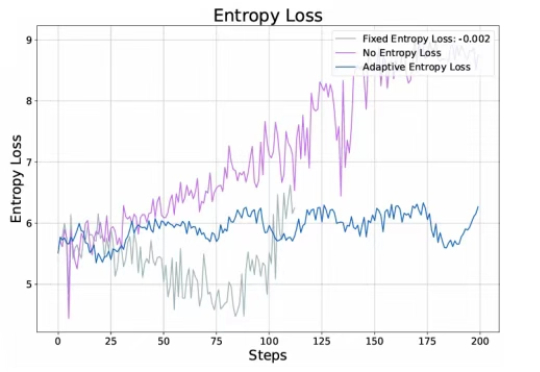
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。