
用 460 万美元追上 GPT-5?Kimi 团队首次回应一切,杨植麟也来了
用 460 万美元追上 GPT-5?Kimi 团队首次回应一切,杨植麟也来了上周 Kimi K2 Thinking 发布,开源模型打败 OpenAI 和 Anthropic,让它社交媒体卷起不小的声浪,网友们都在说它厉害,我们也实测了一波,在智能体、代码和写作能力上确实进步明
来自主题: AI资讯
9760 点击 2025-11-11 11:46
 搜索
搜索
上周 Kimi K2 Thinking 发布,开源模型打败 OpenAI 和 Anthropic,让它社交媒体卷起不小的声浪,网友们都在说它厉害,我们也实测了一波,在智能体、代码和写作能力上确实进步明
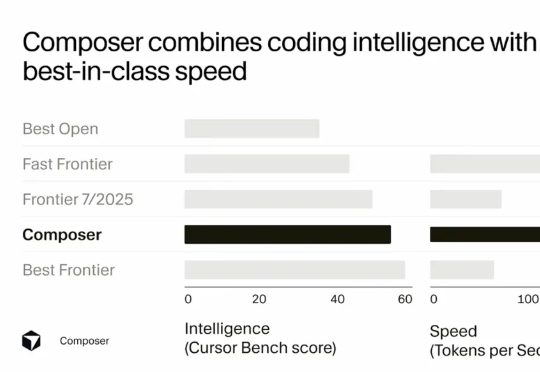
Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。

蚂蚁集团这波操作大圈粉!智东西10月28日报道,10月25日,蚂蚁集团在arXiv上传了一篇技术报告,一股脑将自家2.0系列大模型训练的独家秘籍全盘公开。今年9月至今,蚂蚁集团百灵大模型Ling 2.0系列模型陆续亮相,其万亿参数通用语言模型Ling-1T多项指标位居开源模型的榜首

2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?
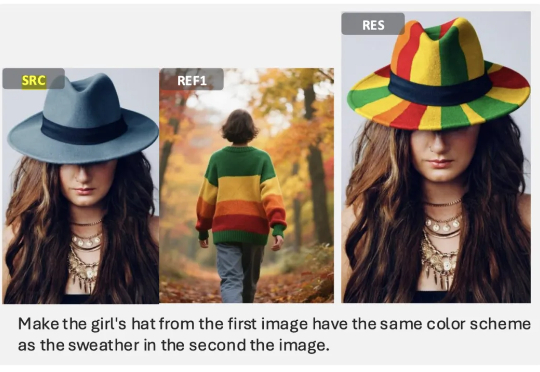
两周前,港科大讲座教授、冯诺依曼研究院院长贾佳亚团队开源了他们的最新成果 DreamOmni2,专门针对当前多模态指令编辑与生成两大方向的短板进行了系统性优化与升级。该系统基于 FLUX-Kontext 训练,保留原有的指令编辑与文生图能力,并拓展出多参考图的生成编辑能力,给予了创作者更高的灵活性与可玩性。
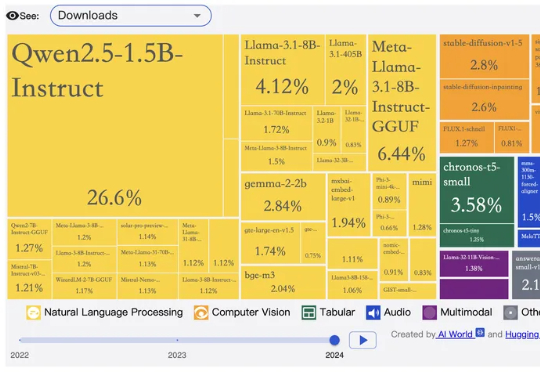
美国 AI 圈开始出现“担心中国开源断供”的苗头了吗?10 月 20 日,在专注于开源模型讨论、拥有 55 万成员的 Reddit 分论坛“r/LocalLLaMA”上,一位网友发布了一则“当中国公司停止提供开源模型时会发生什么?”的提问,并表达了假如中国模型逐渐闭源或开始收费该怎么办的担忧。

OpenAI的封闭模型在IOI 2025竞赛夺金的同时,英伟达团队交出了一份同样令人振奋的答卷——他们利用完全开源的大模型和全新的GenCluster策略,在IOI 2025竞赛中跑出了媲美金牌选手的成绩!开源模型首次达到了IOI金牌水准。这究竟是怎样实现的?
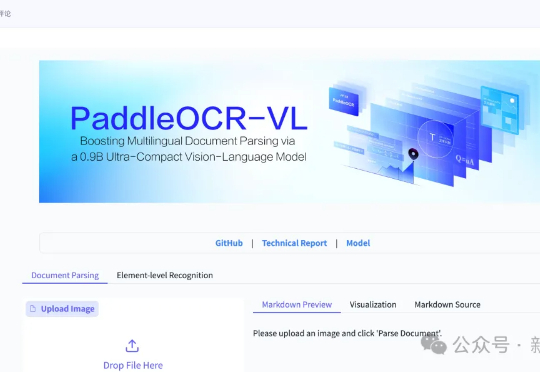
百度登顶全球第一!最新模型「PaddleOCR-VL」以0.9B参数量,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。
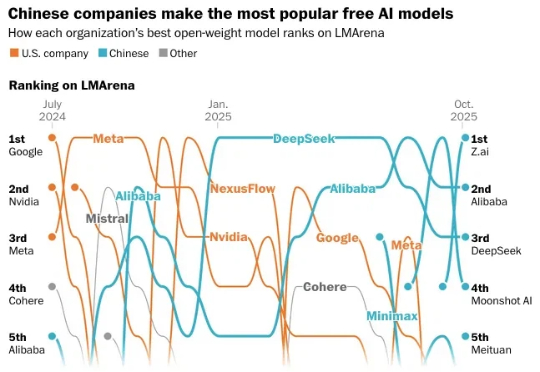
开源大模型,进入中国时间。 10月,公开数据显示,来自中国的开源大模型已经牢牢占据榜单前五。 阿里的Qwen系列和DeepSeek,更是从2024年下半年起,就在开源社区构建起越来越深远的影响力。