
奥特曼:我不会让儿子和AI交朋友!与丈夫的家庭生活首曝光
奥特曼:我不会让儿子和AI交朋友!与丈夫的家庭生活首曝光最近,奥特曼再次出席美国国会山听证会。他对美国政府呼吁:一定要放开监管,过早设定标准,对美国AI将是一场灾难!另外他还透露,OpenAI第一个开源模型,会在今年夏天发布。值得一提的是,奥特曼神秘的家庭生活,也在一位记者的亲身探寻下,让我们窥到了一斑。
来自主题: AI资讯
9668 点击 2025-05-11 10:10
 搜索
搜索
最近,奥特曼再次出席美国国会山听证会。他对美国政府呼吁:一定要放开监管,过早设定标准,对美国AI将是一场灾难!另外他还透露,OpenAI第一个开源模型,会在今年夏天发布。值得一提的是,奥特曼神秘的家庭生活,也在一位记者的亲身探寻下,让我们窥到了一斑。
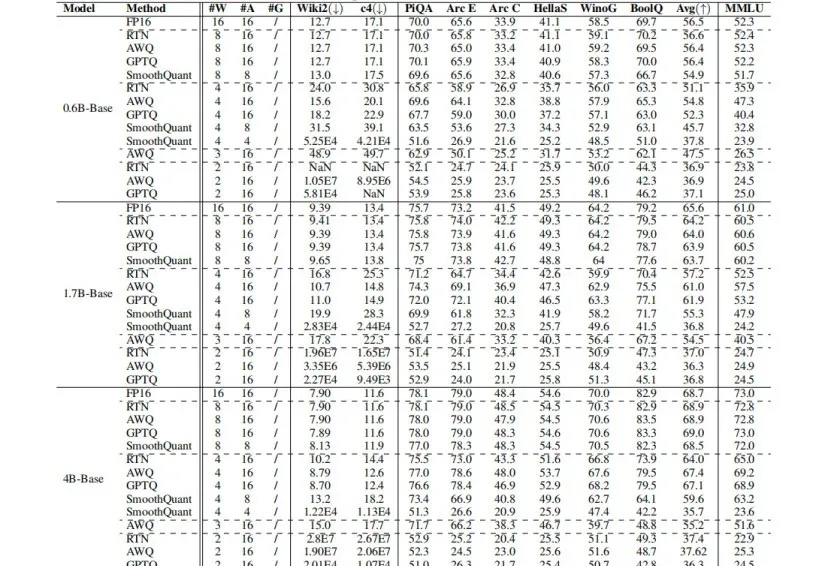
Qwen3强势刷新开源模型SOTA,但如何让其在资源受限场景中,既能实现低比特量化,又能保证模型“智商”不掉线?
今天上午,小米发布了其首个开源推理大模型-Xiaomi MiMo。通过 25 T 预训练 + MTP 加速 + 规则化 RL + Seamless Rollout,让 7 B 参数的 MiMo-7B 在数理推理和代码生成上赶超 30 B-32 B 大模型,并完整 MIT 开源全系列与工程链,给端-云一体 AI 落地提供了“以小博大”的新范例。
一觉醒来,全球开源的王座更替了,不是 R2。好消息是,中国用户依然是最大的受益者。

阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。

可以生成无限时长的视频生成模型终于来了!

4月18日,北京市人工智能产业投资基金宣布:追加投资智谱(Z.ai)2亿元人民币。随后这一消息引发市场热议,因为这笔投资有点“特殊”。此次投资明确指向"开源模型研发与开源社区生态建设",而非通常的技术研发或商业扩张。
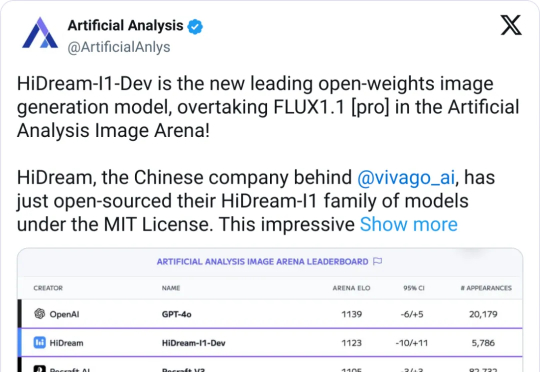
刚出道的 HiDream-I1,拿下了 Hugging Face 趋势榜第二(图像榜第一),Artificial Analysis 文生图第二,排在Midjourney、Google Imagen、FLUX、SDXL 之前,仅次于 GPT-4o 。

前段时间,GPT-4o 火出了圈,其断崖式提升的生图、改图能力让每个人都想尝试一下。虽然 OpenAI 后来宣布免费用户也可以用,但出图慢、次数受限仍然困扰着没有订阅 ChatGPT 的普通人。

代码截图泄露,满血版o3、o4-mini锁定下周!更劲爆的是,一款据称是OpenAI的神秘模型一夜爆红,每日处理高达260亿token,是Claude用量4倍。奥特曼在TED放话:将推超强开源模型,直面DeepSeek挑战。