我MiniMax,用实习生处理数据,照样屠榜开源大模型
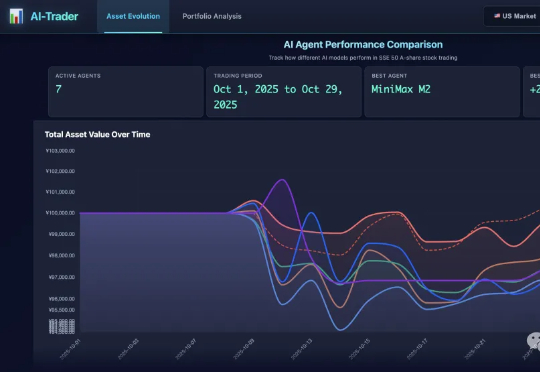
我MiniMax,用实习生处理数据,照样屠榜开源大模型屠榜开源大模型的MiniMax M2是怎样炼成的?为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了? 面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。
来自主题: AI资讯
9075 点击 2025-11-04 20:23
 搜索
搜索
屠榜开源大模型的MiniMax M2是怎样炼成的?为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了? 面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。
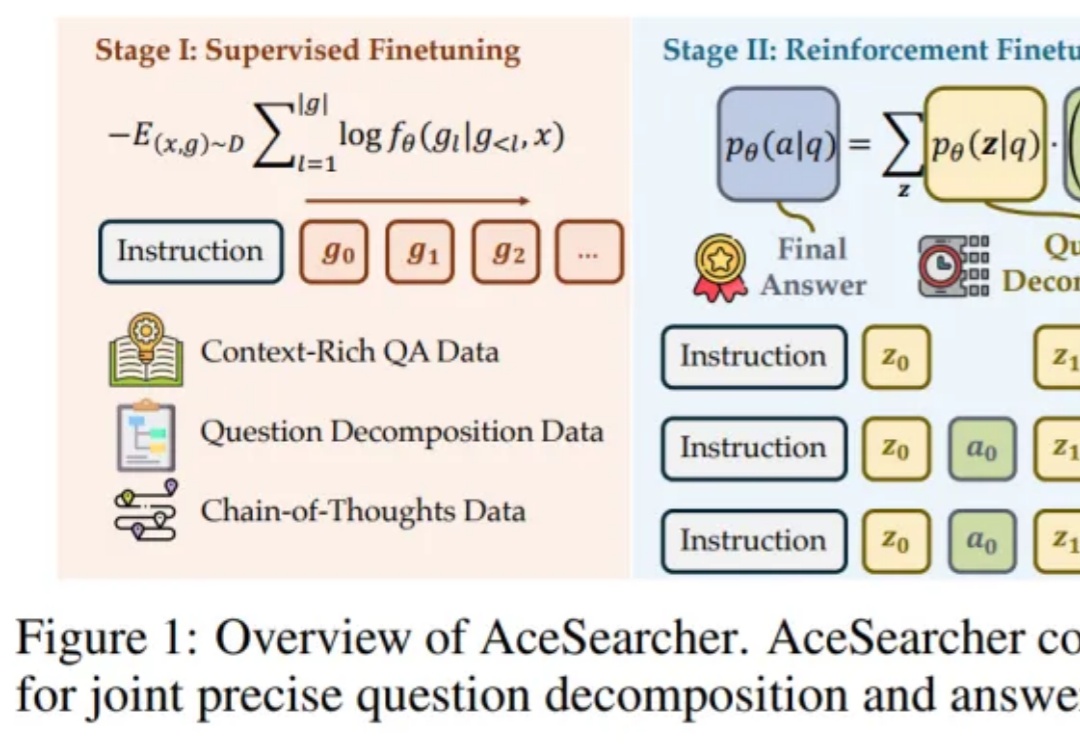
如何让一个并不巨大的开源大模型,在面对需要多步检索与复杂逻辑整合的问题时,依然像 “冷静的研究员” 那样先拆解、再查证、后归纳,最后给出可核实的结论?
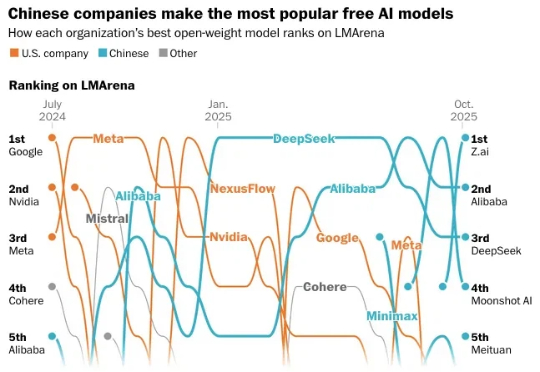
开源大模型,进入中国时间。 10月,公开数据显示,来自中国的开源大模型已经牢牢占据榜单前五。 阿里的Qwen系列和DeepSeek,更是从2024年下半年起,就在开源社区构建起越来越深远的影响力。
啊?今天早上9点多的时候。 美团上线了他们的首个生活类Agent。 名字,叫小美。 大厂们卷疯了。 这战场,真的从WAIMAI打到了AI了我靠。 而且还真的居然被我猜中了。 我上周写过美团的开源大模型
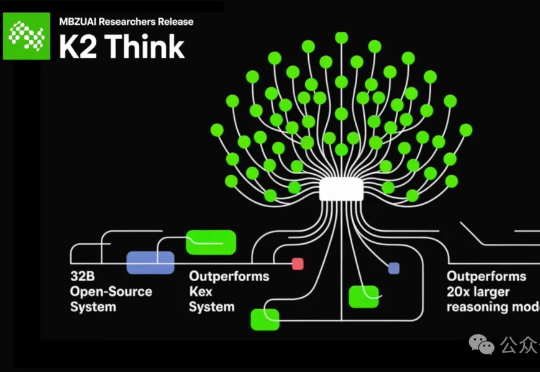
全球最快的开源大模型来了——速度达到了每秒2000个tokens! 虽然只有320亿参数(32B),吞吐量却是超过典型GPU部署的10倍以上的那种。它就是由阿联酋的穆罕默德·本·扎耶德人工智能大学(MBZUAI)和初创公司G42 AI合作推出的K2 Think。
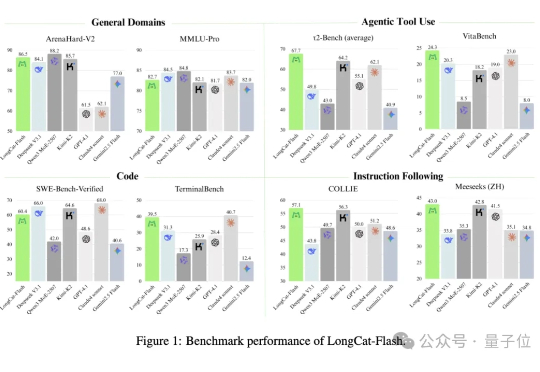
没想到啊,最新SOTA的开源大模型…… 来自一个送外卖(Waimai)的——有两个AI,确实不一样。 这个最新开源模型叫:Longcat-Flash-Chat,美团第一个开源大模型,发布即开源,已经在海内外的技术圈子里火爆热议了。
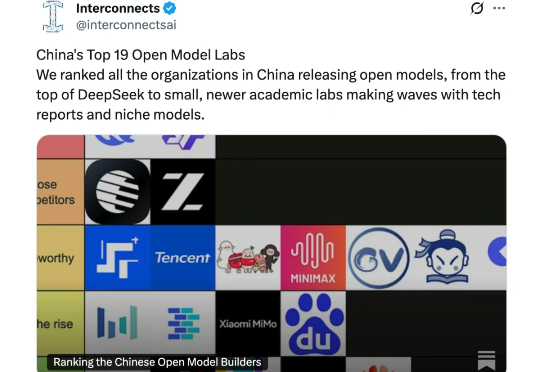
近日,随着新一代大语言模型(LLM)的一波更新,开源大模型再次成为了热门讨论话题。软件工程师、自媒体 Rohan Paul 发现了一个惊人的现象:Design Arena 排行榜上排名前十几位开源 AI 模型全部来自中国。
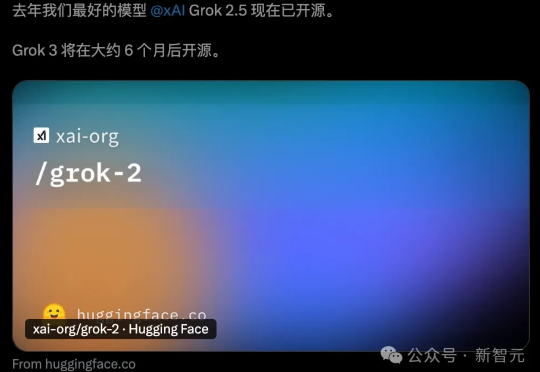
Grok-2正式开源,登上Hugging Face,9050亿参数+128k上下文有多猛?近万亿参数「巨兽」性能首曝。马斯克再现「超人」速度,AI帝国正在崛起。

今天凌晨,OpenAI 甩出一对王炸,正式发布两款开源模型:gpt-oss-120b 和 gpt-oss-20b。是的,你没看错,那个曾经被戏称为 CloseAI 的男人,带着他的诚意,回来了!
家人们!燃起来了燃起来了! 今天,HuggingFace的开源大模型排行榜前10名中,竟有9个席位被中国模型占据!(深挖了一下,另外一位也是我们华人大神的项目)