
Claude当上小店店主,不仅经营不善,还一度相信自己是真实人类
Claude当上小店店主,不仅经营不善,还一度相信自己是真实人类Anthropic 最近做了一项相当有趣的研究:让 Claude 管理其办公室的一家自动化商店。Claude 作为小店店主,运营了一个月,过程也是相当跌荡起伏,甚至在其中的一个时间段,Claude 竟然确信自己是一个真实存在的人类,并幻觉了一些并未发生过的事件。
来自主题: AI资讯
8426 点击 2025-06-28 18:04
 搜索
搜索
Anthropic 最近做了一项相当有趣的研究:让 Claude 管理其办公室的一家自动化商店。Claude 作为小店店主,运营了一个月,过程也是相当跌荡起伏,甚至在其中的一个时间段,Claude 竟然确信自己是一个真实存在的人类,并幻觉了一些并未发生过的事件。
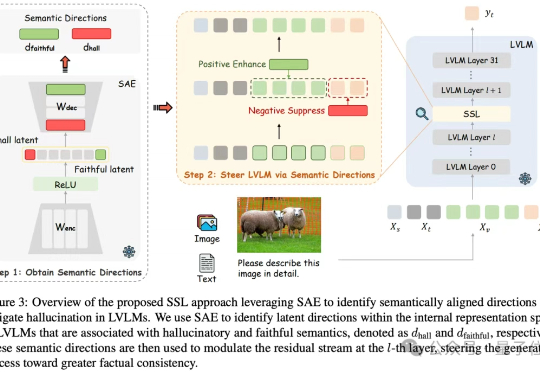
通过“视觉神经增强”机制,直接放大模型中的视觉关键注意力头输出,显著降低模型的幻觉现象。

当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。

豆包、文心一言、DeepSeek、元宝……这些国产AI工具,正在大规模进入职场内容流里。我们以为它们是工具,其实它们更像是一种“说得太像真的语气”,让每个使用者都可能在不经意间交出判断力。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……
为什么我们需要智能写作Agent?

搞RAG开发,一个被普遍忽视却又至关重要的痛点是:如何避免Token分块带来的语义割裂问题。SAT模型通过神经网络驱动的智能分段技术,巧妙解决了这一难题。它不是RAG的替代,而是RAG的强力前置增强层,通过确保每个文本块的语义完整性,显著降低下游生成的幻觉风险。

Rubrik 联合创始人 Soham Mazumdar 于 2023 年离职后,创立了一家名为 WisdomAI 的新数据初创公司。
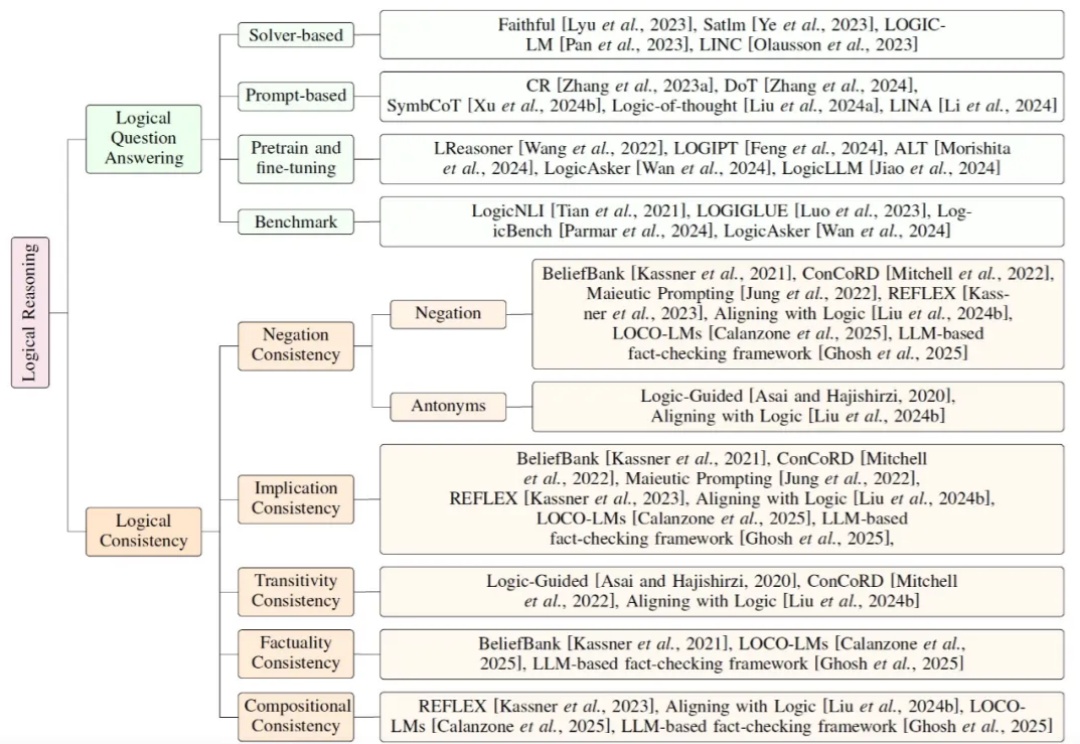
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。