
OpenAI重磅揭秘:你认为的AI幻觉,可能是模型故意出错
OpenAI重磅揭秘:你认为的AI幻觉,可能是模型故意出错你以为AI答错就一定是幻觉?不,它也可能是在故意骗你。
来自主题: AI技术研报
9660 点击 2026-03-26 10:50
 搜索
搜索
你以为AI答错就一定是幻觉?不,它也可能是在故意骗你。
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。

GPT-5.3 Instant不卷跑分,专治「聊天翻车」:不再动不动拒绝回答,不再满嘴说教免责,幻觉率暴降27%,写作能力也跳了一个台阶。

本周四,百川智能正式发布新一代大模型 Baichuan-M3 Plus,其面向医疗应用开发者,在真实场景下将医学问题推理能力推向了全新高度。新模型发布的同时,接入 M3 Plus 的百小应 App 与网页版也已同步上线。

现在,我们越来越多地将大语言模型应用于搜索、编程、内容生成和决策辅助等现实场景中。尽管每天有数百万人使用大模型,但它的问题也随之而来,例如有时会产生幻觉,甚至在特定情境下表现出误导或欺骗用户的倾向。
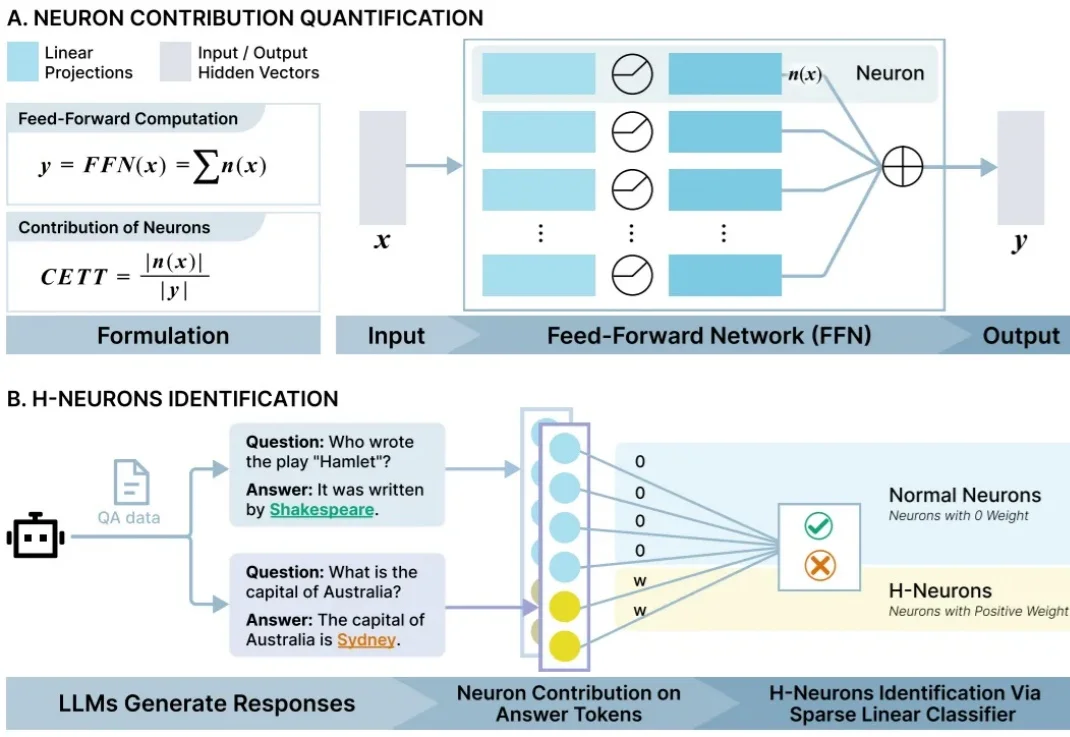
近日,清华大学团队从 AI 里找到了与幻觉产生高度关联的少数“脑细胞”,并给它们起了一个名字 H-神经元(幻觉神经元)。他们发现拨动这些小开关能显著调节 AI 的行为倾向——例如影响它是否会盲目听从错误指令、甚至是否会产生有害回答。

FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!

近日,在与数学家Hannah Fry的对话中,DeepMind CEO Demis Hassabis回顾了AI在过去一年的飞跃式进展,他谈到了「参差智能」、持续学习、模型幻觉等迈向AGI过程中的关键挑战,并提到AGI带来的社会冲击可能是工业革命的10倍。