Deepmind 重磅开源:消除幻觉,让 LLMs 学会规则库和多步推理
Deepmind 重磅开源:消除幻觉,让 LLMs 学会规则库和多步推理大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。
来自主题: AI技术研报
9331 点击 2024-12-30 10:39
 搜索
搜索
大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。
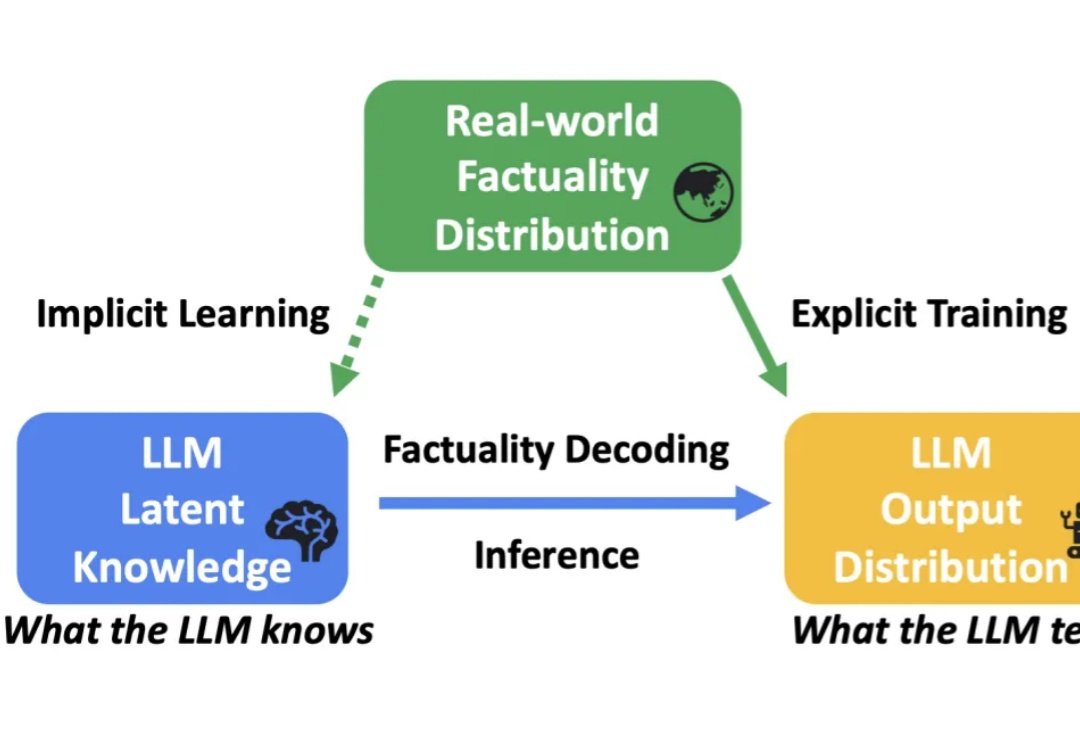
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。

人工智能虽然其提供了广泛的信息,却缺乏解决复杂问题所需的深入、结构化的推理能力,同时还存幻觉的局限。形式逻辑和相关数学工具为 AGI 的逻辑推理能力提供了必要的理论基础和技术支撑。
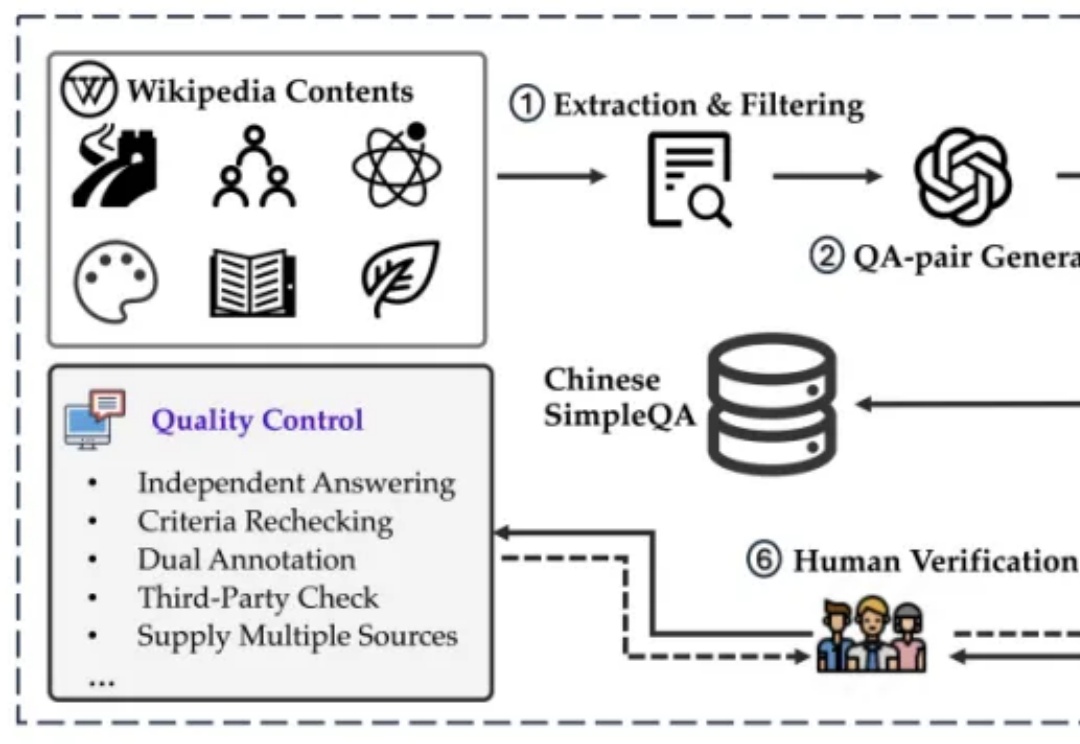
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。

在AI来了之后,其实对各行各业的挑战都非常大,因为很多情况都是第一次出现,之前并没有案例可以参考。例如我这两天看到我的律师同学转发了一条新闻,是关于一群懂技术的律师利用AI的漏洞来牟利,非常有代表性,我给大家简单聊一下。

“过去24个月,AI行业发生的最大变化是什么?是大模型基本消除了幻觉。”11月12日,百度创始人李彦宏在百度世界2024大会上,发表了主题为《应用来了》的演讲,发布两大赋能应用的AI技术:检索增强的文生图技术(iRAG)和无代码工具“秒哒”。文心iRAG用于解决大模型在图片生成上的幻觉问题,极大提升实用性;无代码工具“秒哒”让每个人都拥有程序员的能力,将打造数百万“超级有用”的应用。

Infactory.ai作为一款专注于事实审查的AI搜索引擎,旨在通过使用大语言模型理解搜索意图,而非直接生成搜索结果,以此来提供准确、透明的搜索结果,从根本上避免了搜索结果的幻觉问题,同时依然能提高用户使用搜索工具的效率。

大模型幻觉,究竟是怎么来的?谷歌、苹果等机构研究人员发现,大模型知道的远比表现的要多。它们能够在内部编码正确答案,却依旧输出了错误内容。
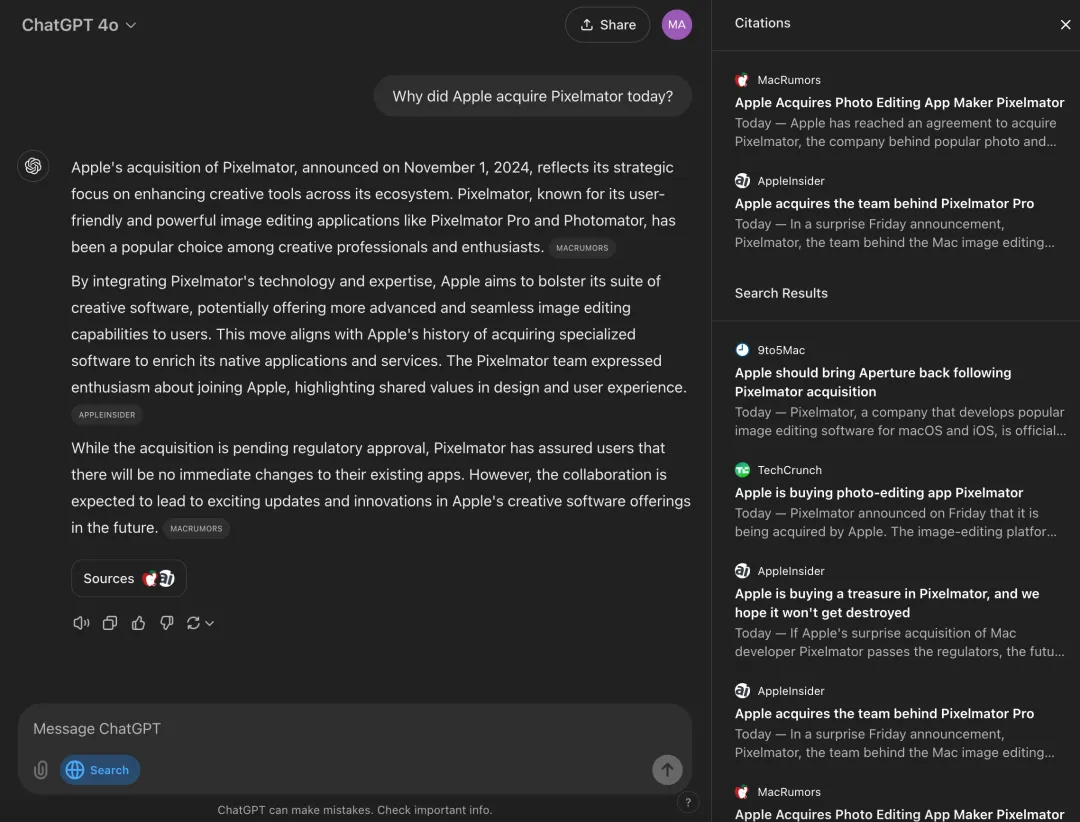
OpenAI 发布了备受期待的搜索产品,ChatGPT 搜索,以挑战谷歌。业界已经为这一时刻准备了几个月,这促使谷歌在今年早些时候将 AI 生成的答案注入其核心产品,并在此过程中产生了一些尴尬的幻觉。这一失误让许多人相信 OpenAI 的搜索引擎将真正成为“谷歌大杀器”。