
老黄不只卖铲子了!英伟达要当AI产业链的「收租人」
老黄不只卖铲子了!英伟达要当AI产业链的「收租人」刚刚,英伟达再次甩出一份炸裂财报:单季营收816亿美元,光数据中心一项就占了92%。但真正应当注意的,是财报中一个一年翻了近29倍的数字。它背后,是英伟达正在悄悄完成的身份转换:从「卖铲子的人」,变成整条AI产业链的「收租人」。
来自主题: AI资讯
9124 点击 2026-05-28 10:20
 搜索
搜索
刚刚,英伟达再次甩出一份炸裂财报:单季营收816亿美元,光数据中心一项就占了92%。但真正应当注意的,是财报中一个一年翻了近29倍的数字。它背后,是英伟达正在悄悄完成的身份转换:从「卖铲子的人」,变成整条AI产业链的「收租人」。
迈入今年618大促周期,各大电商平台纷纷加码AI购物,智能选购成为各家角逐的新焦点。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

距离谷歌的Gemini 3.5 Flash发布已经一周多了。
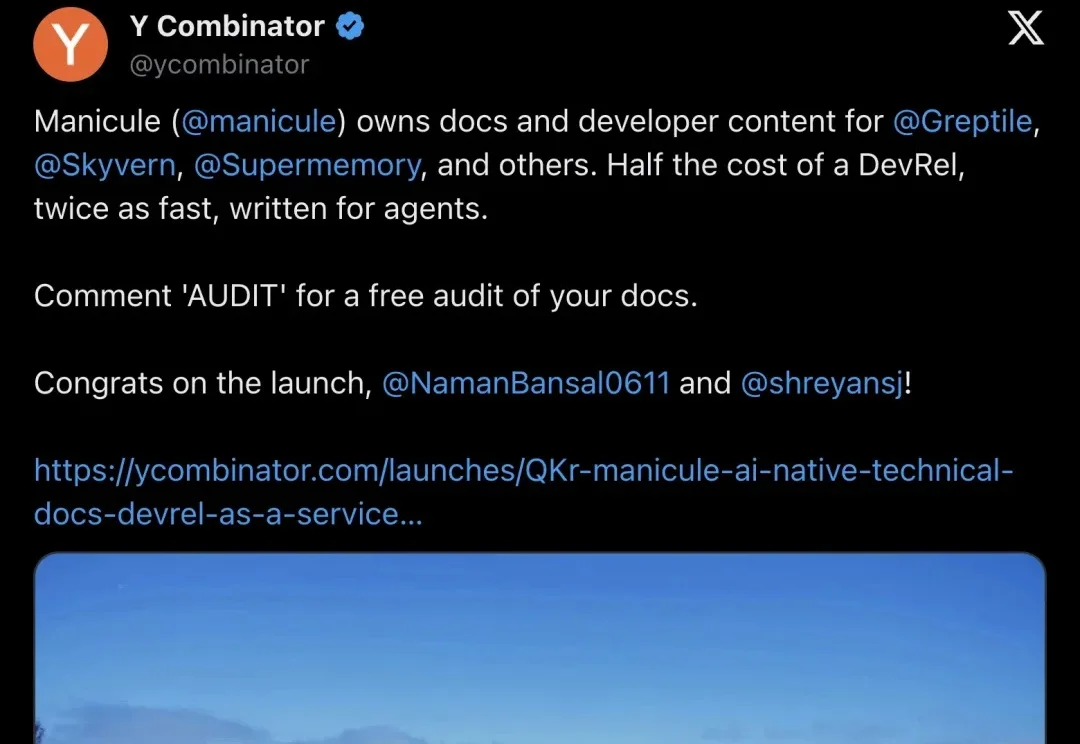
YC 官方账号亲自下场推了一家叫 Manicule 的公司——专门给开发者工具团队承包技术文档和 DevRel 内容,核心卖点:成本只要 DevRel 的一半,速度快一倍,而且文档专门为 AI agent 优化。当 Codex、Claude Code 这些编程 agent 开始直接读你的 docs 来调 API,文档质量差就等于把客户拱手让给竞品。

5 月 22 日,星巴克在内部通讯中正式通知北美 1.1 万家门店:立即停止使用名为 “自动计数(AC)” 的 AI 库存工具,所有饮品原料(糖浆、牛奶、浇头等)回归人工盘点。

OpenAI要发力营销了!

智能体时代,如何让视觉分割更准确?

80分钟的拳击式辩论!Transformer联合发明人亲自下场为自己的作品辩护,对面三位挑战者直指五大死穴。这是AI架构十年来最硬的一次正面交锋。统治AI黄金十年的架构,地基是不是已经松了?

众所周知,大模型训练成本极高。