
特朗普政府,拟入股OpenAI
特朗普政府,拟入股OpenAI据彭博社报道,美国总统特朗普表示有意让美国政府持有领先AI公司的股权,并称他计划最早下周与AI公司高管讨论合作的想法。周五,特朗普在空军一号上被记者问到此事时谈道:“有些方案可以将部分股份赠予美国公众,让美国公众实际上成为合作伙伴。这很有意思,它几乎可以与美国公众建立伙伴关系,我们会研究一下。”
来自主题: AI资讯
9318 点击 2026-06-06 10:29
 搜索
搜索
据彭博社报道,美国总统特朗普表示有意让美国政府持有领先AI公司的股权,并称他计划最早下周与AI公司高管讨论合作的想法。周五,特朗普在空军一号上被记者问到此事时谈道:“有些方案可以将部分股份赠予美国公众,让美国公众实际上成为合作伙伴。这很有意思,它几乎可以与美国公众建立伙伴关系,我们会研究一下。”

智东西6月6日消息,据《福布斯》今日报道,瑞典明星AI氛围编程创企Lovable正在洽谈融资,估值将达到120亿美元(约合人民币812亿元)。四位消息人士透露,新资金注入将使Lovable的估值几乎翻番,高于去年12月的66亿美元(约合人民币447亿元)。
在代码世界里 Debug 已经不能满足硅谷了。2026 年 5 月底,谷歌向美国环境保护署(EPA)提交了一份实验使用许可申请:他们计划在未来两年内,向美国佛罗里达州和加利福尼亚州放飞 3,200 万只被一种特殊细菌感染过的雄性蚊子,在真实世界里“Debug”。
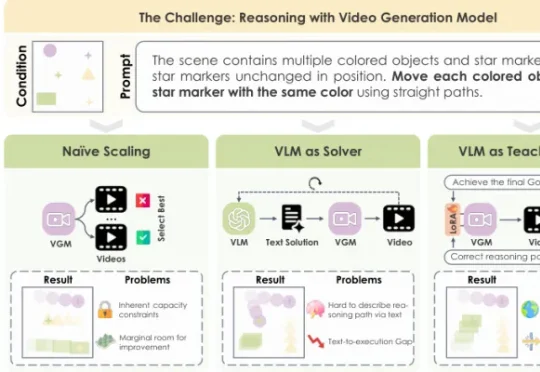
怎么让VGM学会按规则推理?过去主要有两条路。两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。
终于看到一个跳出 Codex、Claude Code 这些 Agent 范畴的新 AI 产品。而且在海外已经火起来了。这个产品叫 Aippy。目前 MAU 将近两百万,全球下载超过三百万,刚完成首轮融资,投后估值 2.5 亿美元。也是垂类赛道的新独角兽了。

刚刚,AI圈发生了一件很不寻常的事。Sam Altman、Dario Amodei、Demis Hassabis……一群平时打得最凶的人,把名字签在了同一封公开信上。他们联合呼吁美国国会:立法强制筛查所有合成DNA订单。

数学,这块人类心智的荣耀,正面临一场前所未有的「降维打击」。当算法的「非人化」优势把80年的接力变成32小时的副产品时,我们不得不问:人类到底想要一个又一个正确答案,还是想要理解这些答案的过程?

复盘三年多的AI行情,就是一个不断找硬件瓶颈的过程:最开始涨GPU,后来涨服务器,再后来涨数据中心,然后涨电力,接着涨HBM存,现在又开始涨CPU、高速互联和ASIC。
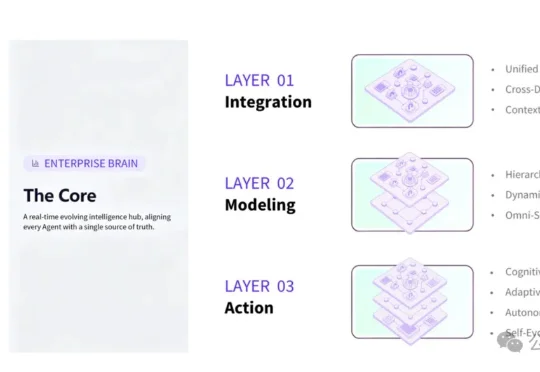
6月5日,百型智能正式发布第三代企业级 AI 基础设施——OntoZ。这款新产品跳出了传统单点SaaS与孤立智能体的产品逻辑,以企业本体为底层基座,搭建可动态自迭代的群智能体协同体系,为企业打造具备自主进化能力的数字生产力底座。

近日,欧拉万象正式宣布再次完成超过亿元的天使轮融资,这也是欧拉万象三个月以来完成的第三轮融资。本轮融资由某产业资本、慕华科创、百度风投、玖兆投资、聚合资本联合投资,老股东持续跟投。这是欧拉万象继获得高瓴创投、五源资本、招商局创投等顶级机构密集加持后,再次迎来市场化与产业资本的重磅加注。