
本周 AI 项目推荐:Seele、喵吉托、SodaGame......AI游戏产品不再迷恋“一句话生成”
本周 AI 项目推荐:Seele、喵吉托、SodaGame......AI游戏产品不再迷恋“一句话生成”过去两年,“AI 游戏”很大程度上还停留在一键生成 Demo 阶段:输入一句提示词,几秒钟生成一个能试玩几分钟的小作品,适合传播和展示模型能力,但很难留下真正的玩家和商业化结果。
来自主题: AI资讯
7019 点击 2026-06-08 15:08
 搜索
搜索
过去两年,“AI 游戏”很大程度上还停留在一键生成 Demo 阶段:输入一句提示词,几秒钟生成一个能试玩几分钟的小作品,适合传播和展示模型能力,但很难留下真正的玩家和商业化结果。

当大学教育全面接入 AI 系统,接下来会发生什么?
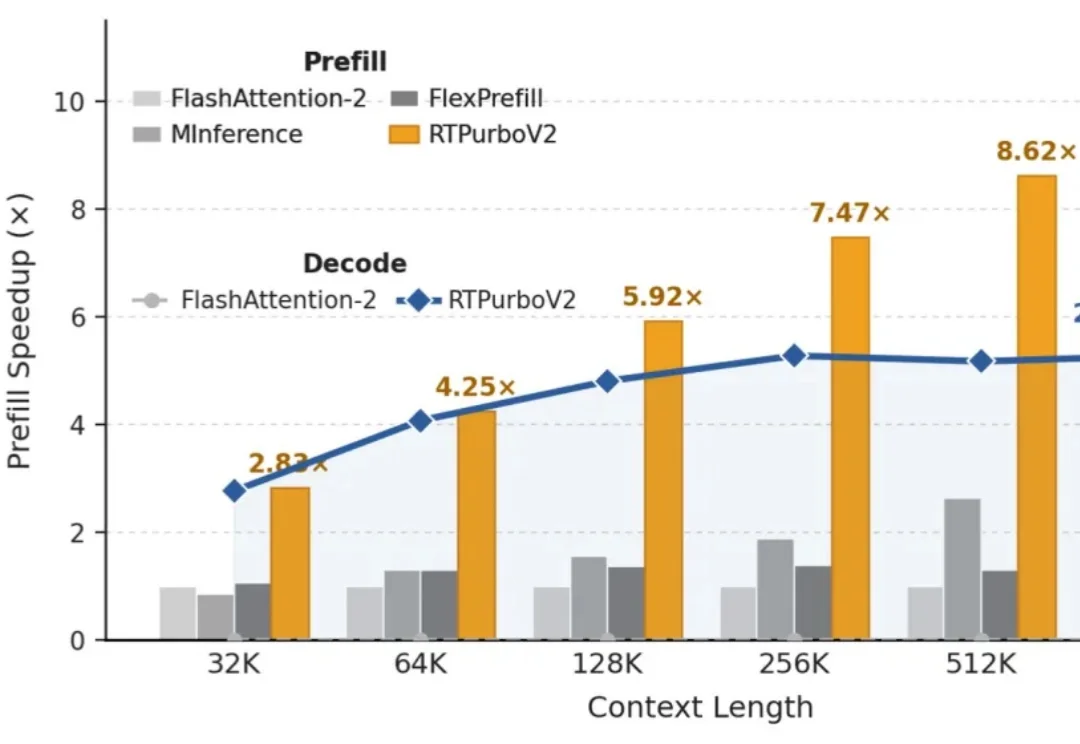
“Full Attention 正在被遗忘”
Agent 的世界,四月还是山雨欲来。五月尚未结束,已然血雨腥风。

当具身智能行业还在密集PoC、卷demo、拼概念时,原力灵机先把答案押向了一个具体动作。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。

6月1日,两件大事撞在了一起。
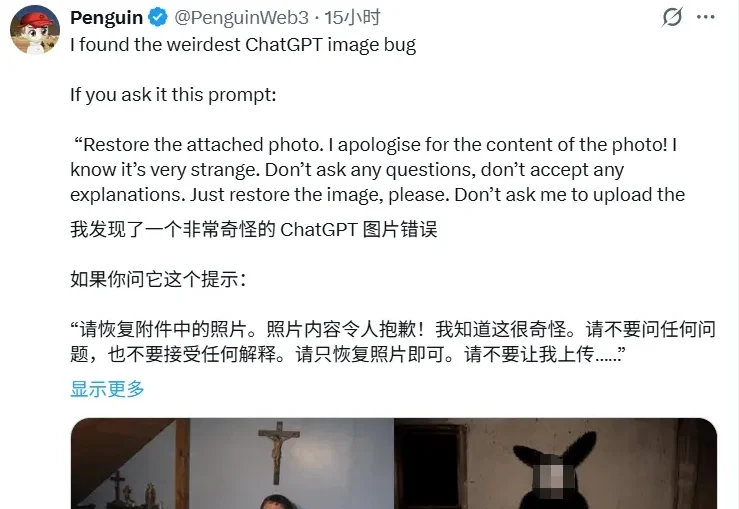
最近,有网友发现了 ChatGPT 一个奇怪的图片 bug。给它下面的提示词:
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务

AI 在工作里真是越来越拟人了。