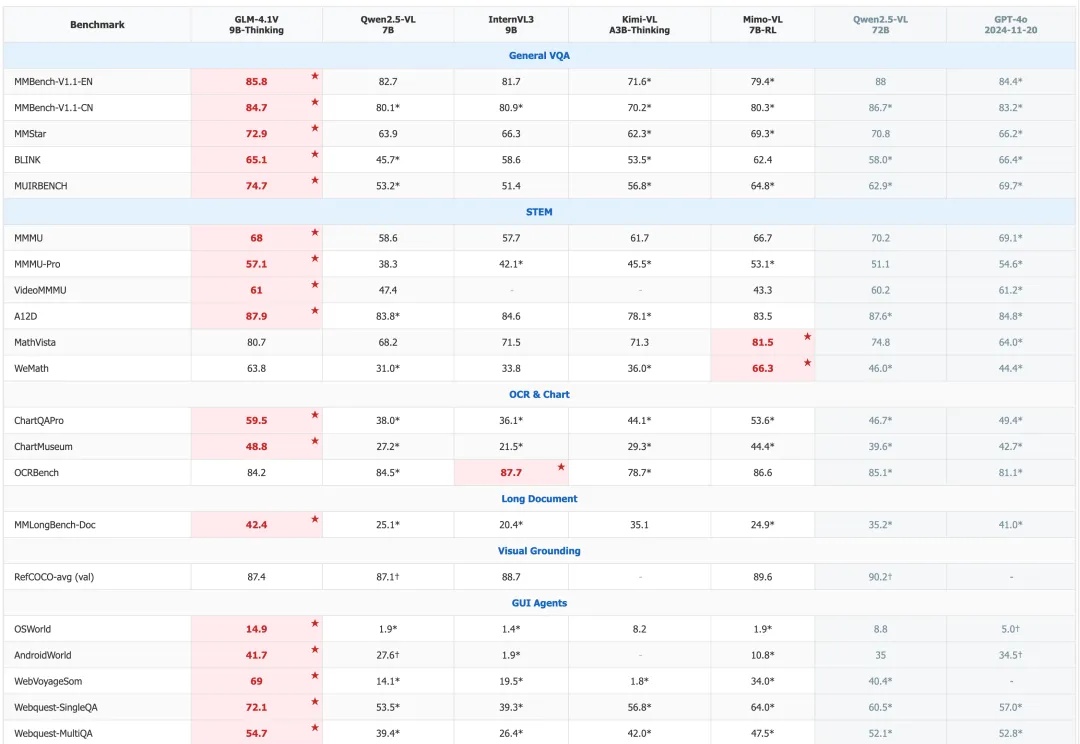
9B“小”模型干了票“大”的:性能超8倍参数模型,拿下23项SOTA | 智谱开源
9B“小”模型干了票“大”的:性能超8倍参数模型,拿下23项SOTA | 智谱开源如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
来自主题: AI技术研报
10547 点击 2025-07-02 15:56
 搜索
搜索
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
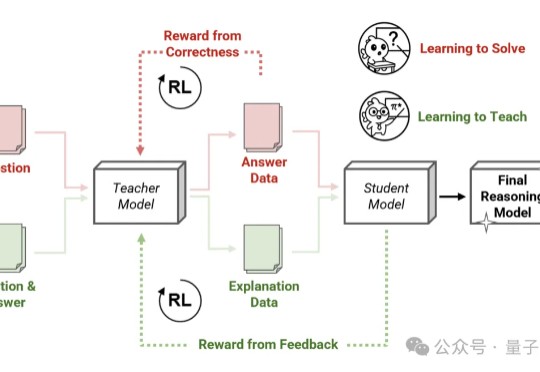
Thinking模式当道,教师模型也该学会“启发式”教学了—— 由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!
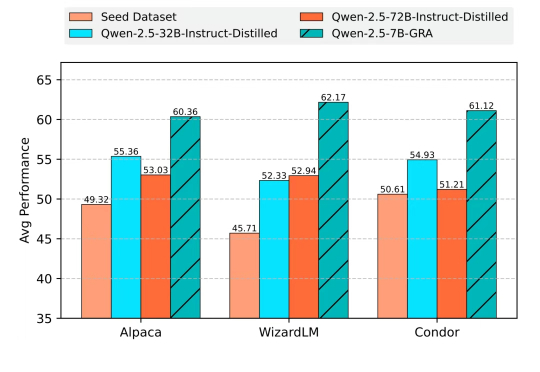
无需蒸馏任何大规模语言模型,小模型也能自给自足、联合提升?

NVIDIA等研究团队提出了一种革命性的AI训练范式——视觉游戏学习ViGaL。通过让7B参数的多模态模型玩贪吃蛇和3D旋转等街机游戏,AI不仅掌握了游戏技巧,还培养出强大的跨领域推理能力,在数学、几何等复杂任务上击败GPT-4o等顶级模型。

Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。
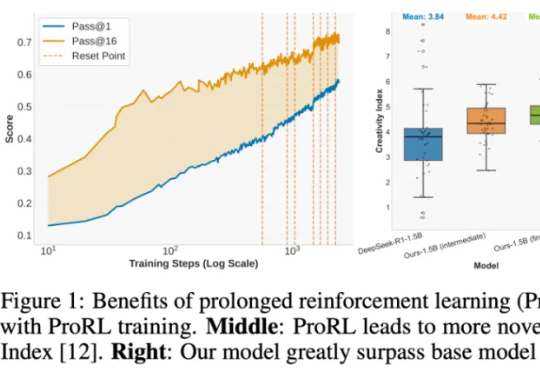
强化学习(RL)到底是语言模型能力进化的「发动机」,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?
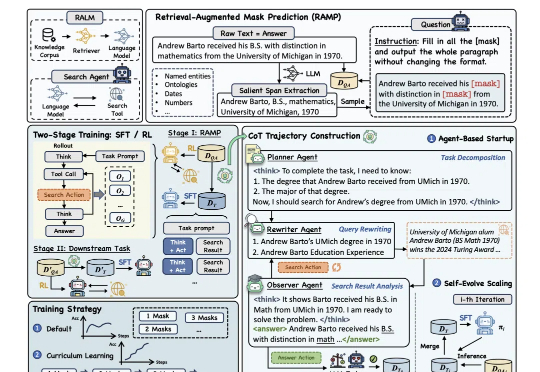
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
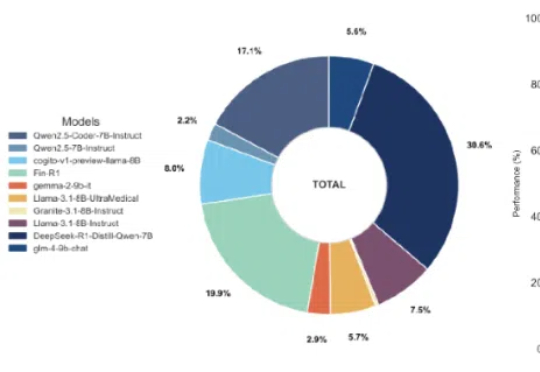
近年来,语言模型技术迅速发展,然而代表性成果如Gemini 2.5Pro和GPT-4.1,逐渐被谷歌、OpenAI等科技巨头所垄断。
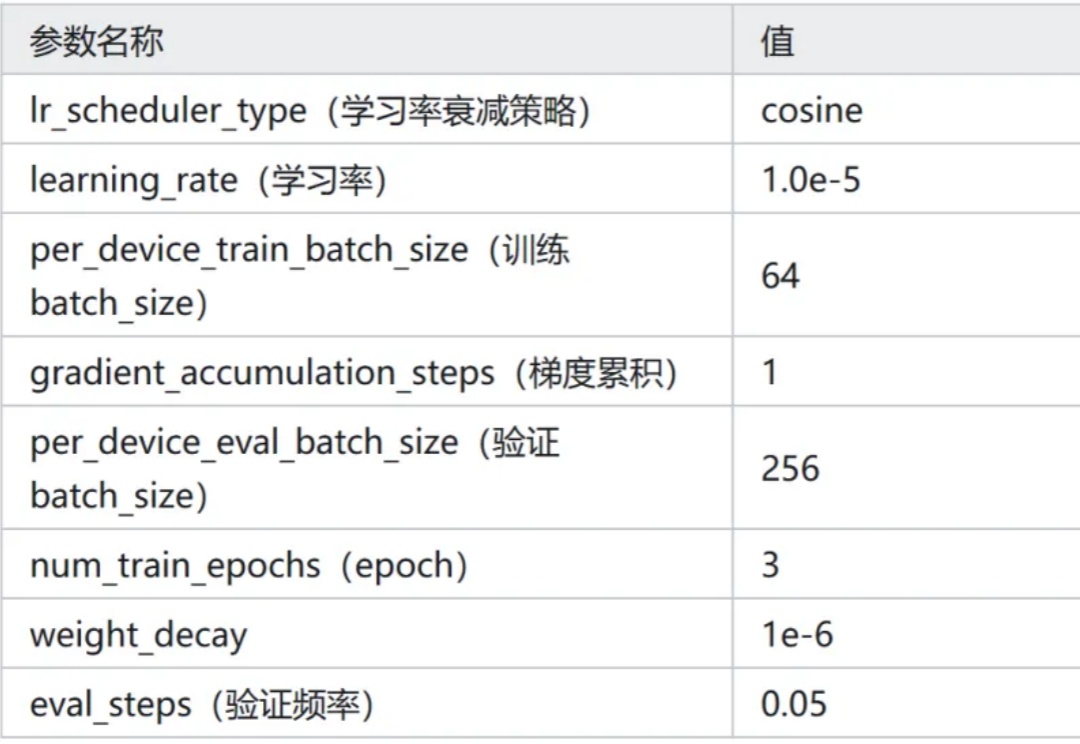
新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。
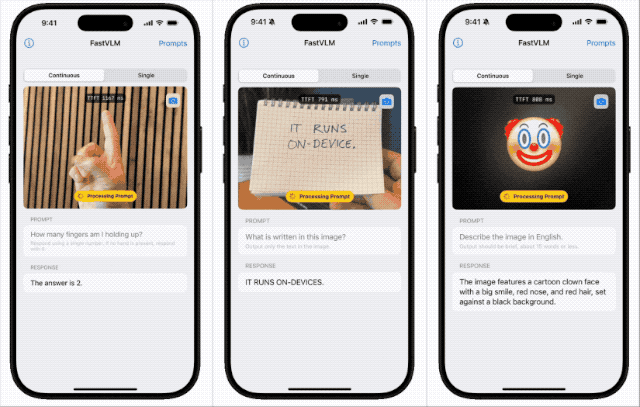
苹果近期开源本地端侧视觉语言模型FastVLM,支持iPhone等设备本地运行,具备快速响应、低延迟和多设备适配特性。该模型依托自研框架MLX和视觉架构FastViT-HD,通过算法优化实现高效推理,或为未来智能眼镜等新硬件铺路,体现苹果将AI深度嵌入系统底层的战略布局。