
不敢对比阿里Qwen2.5,Mistral“最强小模型”陷争议,欧洲的OpenAI也不Open了
不敢对比阿里Qwen2.5,Mistral“最强小模型”陷争议,欧洲的OpenAI也不Open了欧洲的OpenAI,也不Open了。
来自主题: AI资讯
9061 点击 2024-10-17 14:37
 搜索
搜索
欧洲的OpenAI,也不Open了。

微软 10 年「老兵」选择离开。

大语言模型市场的整合与差异:大语言模型市场存在整合的趋势。一方面,人工智能发展的基础产业是资本密集型的,市场整合对于大语言模型市场的资本支撑是必要的。另一方面,为尽可能提高算法的泛化能力,单个大语言模型也需要集成多种创新功能。市场集中度的提高使得企业需要进一步考虑大语言模型的差异化。

不必增加模型参数,计算资源相同,小模型性能超过比它大14倍的模型!

你敢相信 4B 参数小模型,性能却超越千亿量级的 GPT-3.5 !OpenAI、谷歌、微软、苹果等一众海内外巨头还没做到的事,被一家中国大模型公司抢先了!
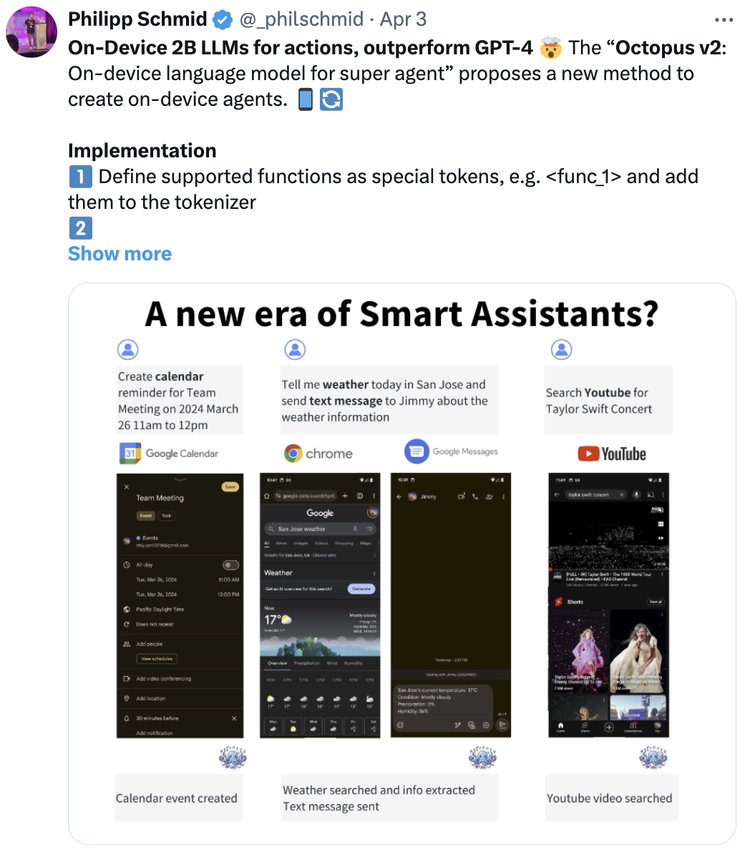
比OpenAI最强的GPT-4o更快,函数调用能力与GPT-4相当,同时比它小N倍,且只需要一张卡来做推理。
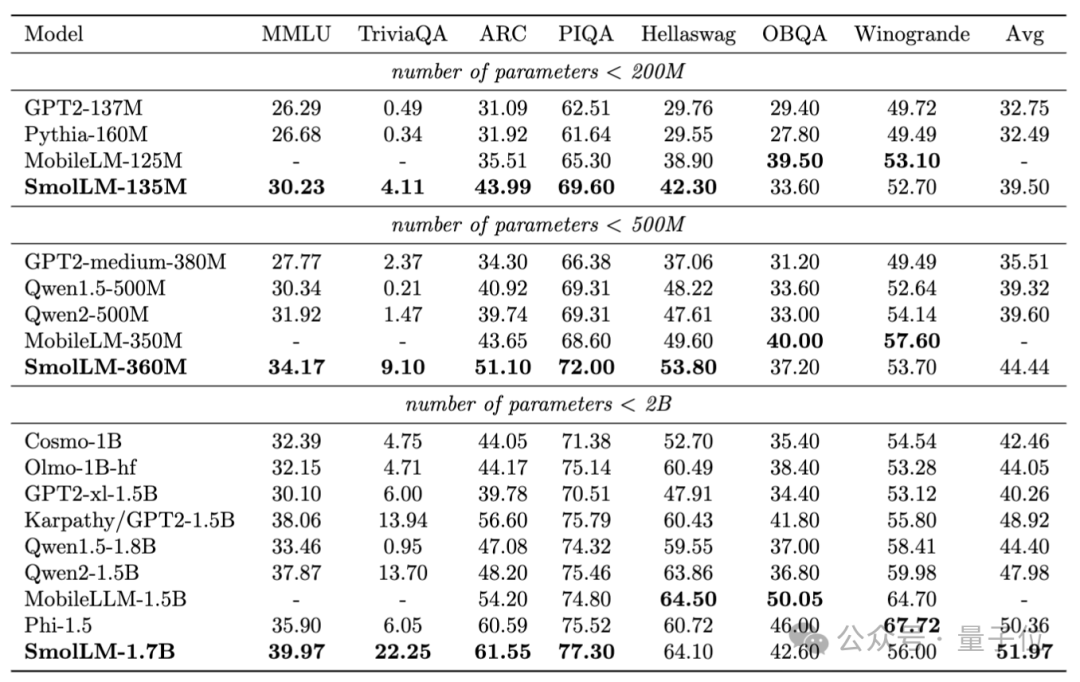
浏览器里直接能跑的SOTA小模型来了,分别在2亿、5亿和20亿级别获胜,抱抱脸出品。

互相检查,让小模型也能解决大问题。
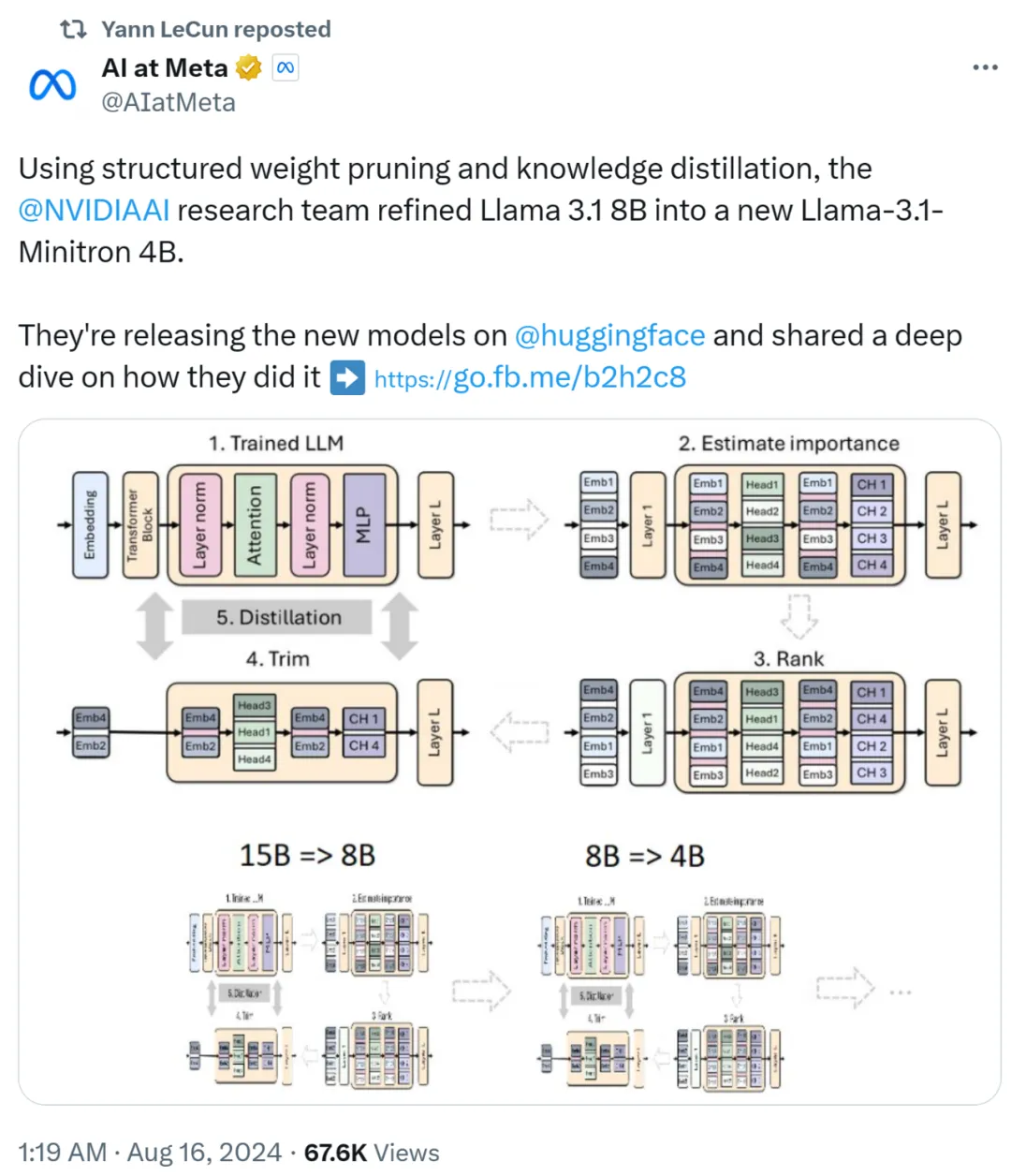
小模型崛起了。

有CPU就能跑大模型,性能甚至超过NPU/GPU!