
用好梯度信息GREATER,小模型也能成为提示词优化高手,PSU最新
用好梯度信息GREATER,小模型也能成为提示词优化高手,PSU最新为了优化小模型的提示词,我们不得不求助于计算成本高昂的大模型。这种依赖不仅增加了开发成本,还限制了小模型的应用场景。
来自主题: AI资讯
11088 点击 2024-12-26 09:48
 搜索
搜索
为了优化小模型的提示词,我们不得不求助于计算成本高昂的大模型。这种依赖不仅增加了开发成本,还限制了小模型的应用场景。
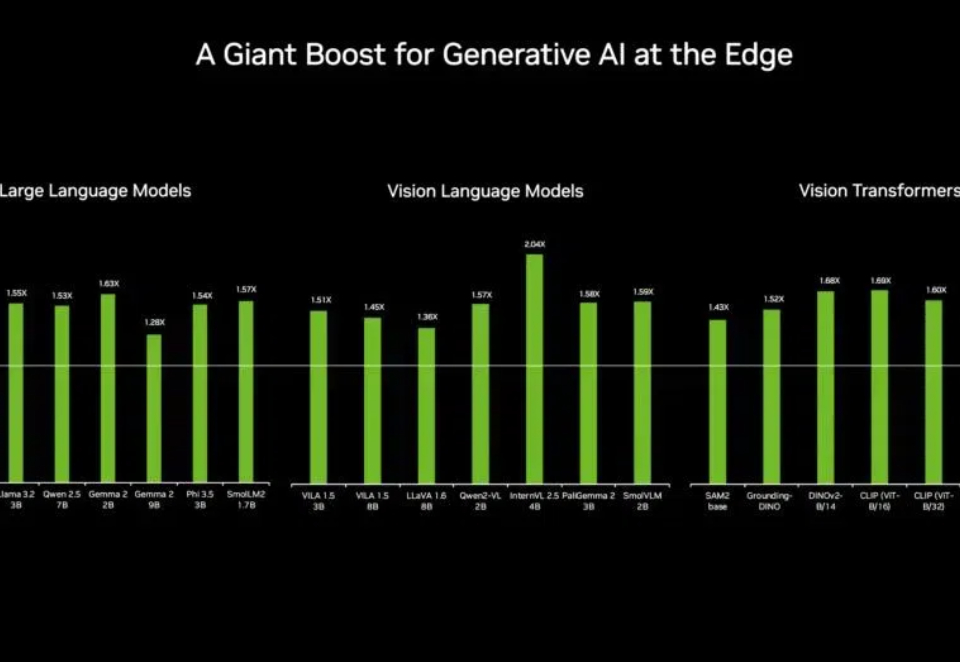
英伟达新品掀起边缘AI开发板大战,也为中国企业在边缘AI领域的发展提供了机遇。 前几篇文章,我们不断探讨小模型(SLM)在端侧和边缘侧的崛起。现在,边缘侧小模型已然成为不可忽视的发展趋势。
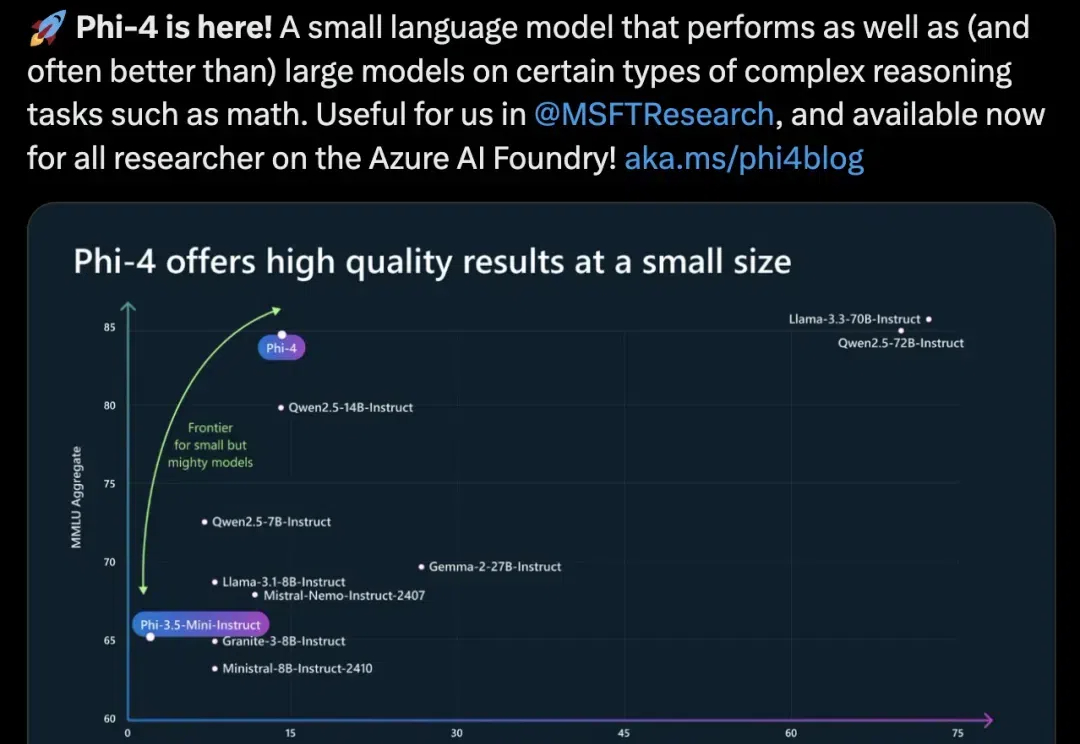
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。

过去一年,强化学习成为了大模型 AI 领域最热的概念之一。 随着行业内高阶推理模型的推出,再次彰显了强化学习在通往 AGI 道路上的重要性,也标志着大模型 AI 进入了一个全新阶段。
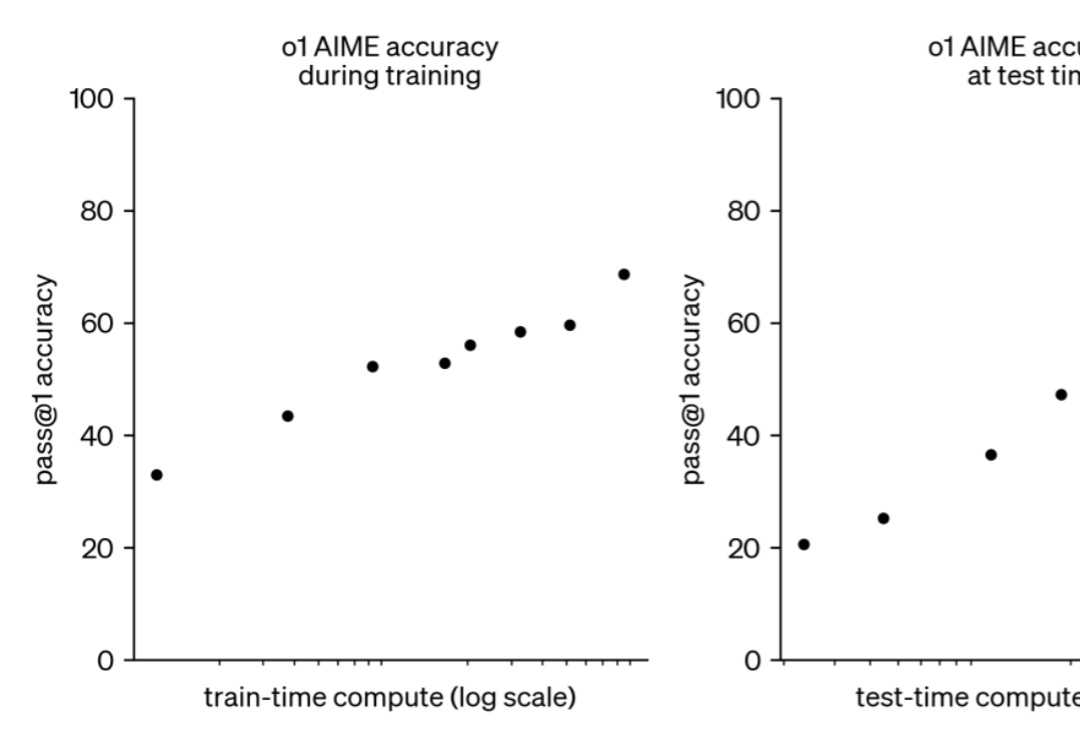
如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。
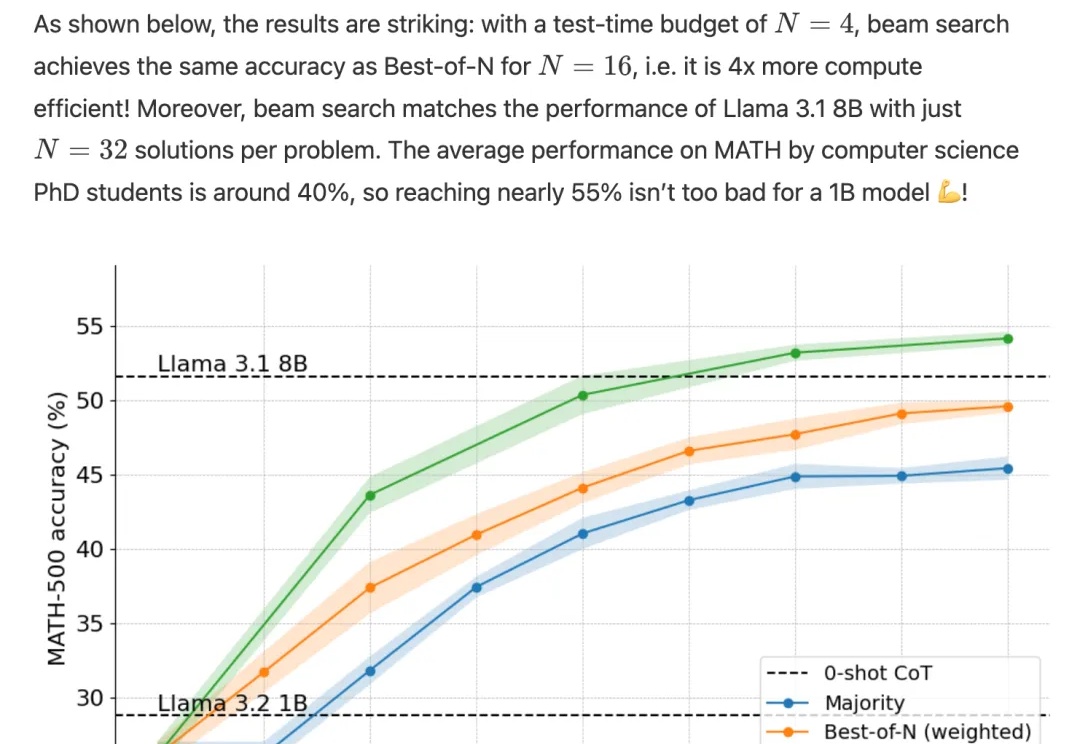
o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!

Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。
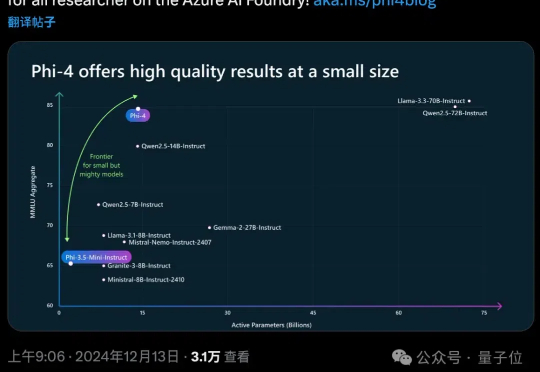
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。
大模型未必最优,小模型也有机会 前几天刷B站的时候,碰到了一个很抽象很难评的事情——一个科普up主的视频里,夹带了一个AI产品的广告。

自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。