
Nano Banana不会应试!指标拉垮,视觉效果惊艳,实测14个任务
Nano Banana不会应试!指标拉垮,视觉效果惊艳,实测14个任务最新报告探讨了生成式模型Nano Banana Pro在低层视觉任务中的表现,如去雾、超分等,传统上依赖PSNR/SSIM等像素级指标。研究发现,Nano Banana Pro在视觉效果上更佳,但传统指标表现欠佳,因生成式模型更追求语义合理而非像素对齐。
来自主题: AI技术研报
10195 点击 2026-01-05 10:17
 搜索
搜索
最新报告探讨了生成式模型Nano Banana Pro在低层视觉任务中的表现,如去雾、超分等,传统上依赖PSNR/SSIM等像素级指标。研究发现,Nano Banana Pro在视觉效果上更佳,但传统指标表现欠佳,因生成式模型更追求语义合理而非像素对齐。
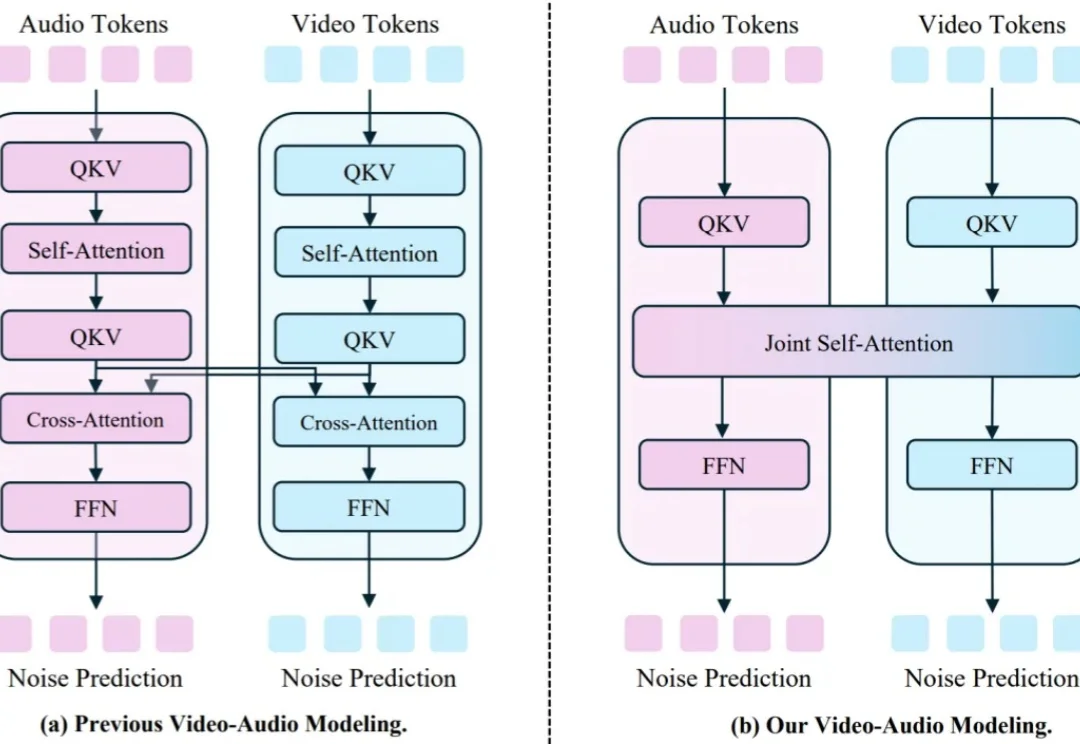
视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。

最近,清华大学教授、智谱AI首席科学家唐杰发了一条长微博,总结了自己2025年对大模型进展的感悟。从预训练到中后训练、长尾场景的对齐能力,再到Agent、多模态和具身智能的发展,其中有不少亮点。
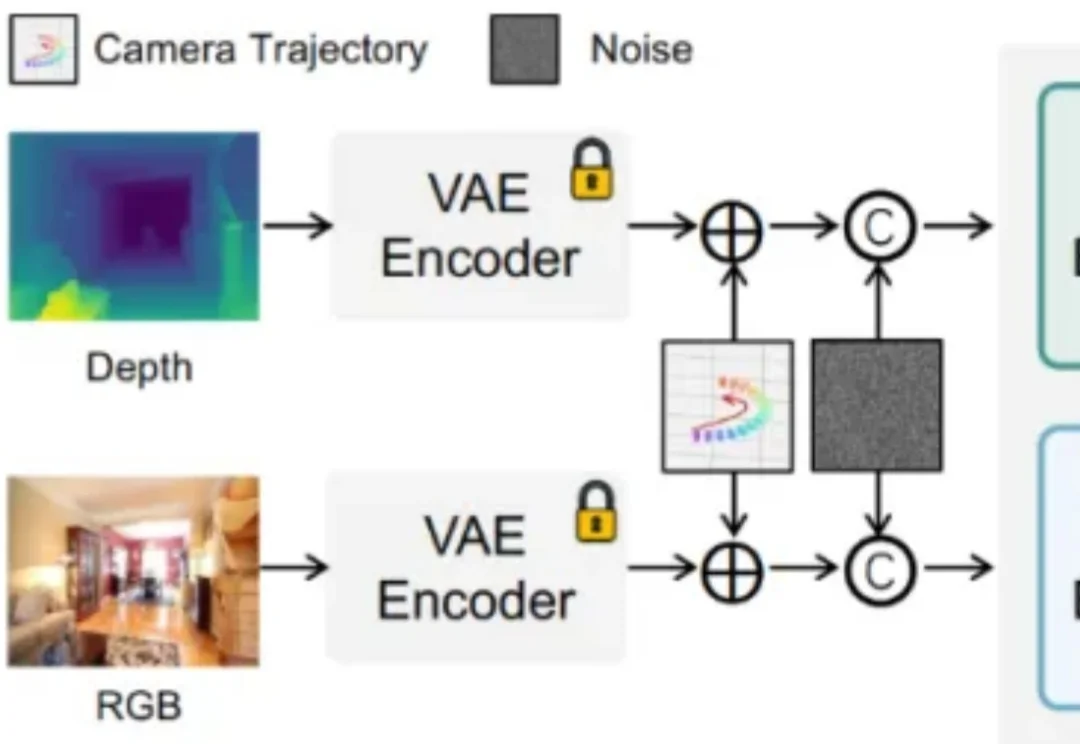
你的生成模型真的「懂几何」吗?还是只是在假装对齐相机轨迹?
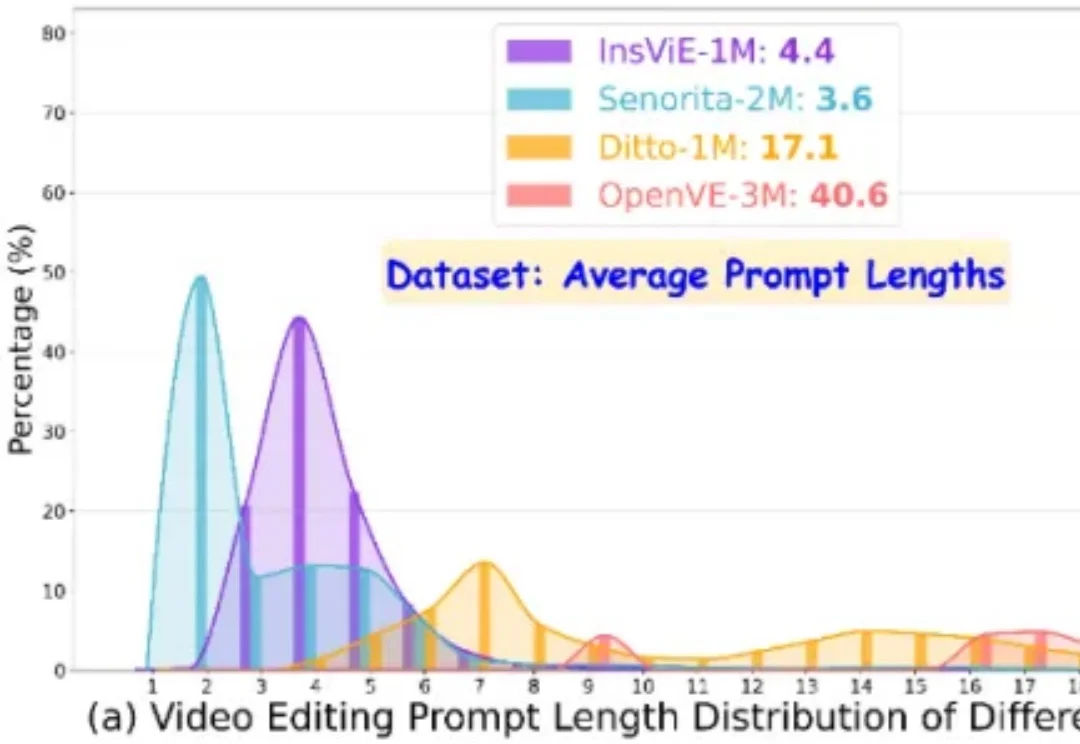
作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。

在Anthropic,有一位驻场哲学家Amanda Askell专门研究如何与AI模型打交道。她不仅主导设计了Claude的性格、对齐与价值观机制,还总结出一些行之有效的提示词技巧。哲学在AI时代不仅没有落伍,反而那些通过哲学训练掌握提示词技巧的人,年薪中位数可以高达15万美元。

在具身智能与视频理解飞速发展的今天,如何让 AI 真正 “看懂” 复杂的操作步骤?北京航空航天大学陆峰教授团队联合东京大学,提出视频理解新框架。该工作引入了 “状态(State)” 作为视觉锚点,解决了抽象文本指令与具象视频之间的对齐难题,已被人工智能顶级会议 AAAI 2026 接收。

最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。
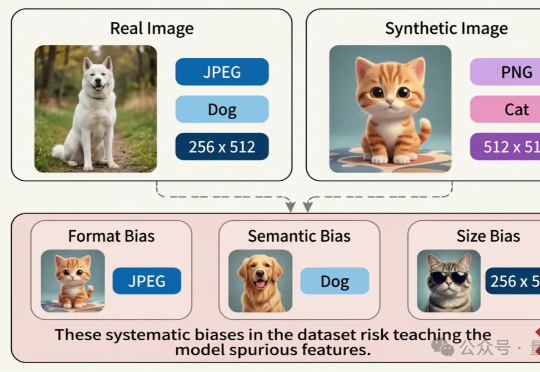
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。