AI视频是否符合物理规律,量化基准来了,实现人类感知对齐 | 阿里高德/中科院出品
AI视频是否符合物理规律,量化基准来了,实现人类感知对齐 | 阿里高德/中科院出品测一测现有AI生成视频是否符合物理运动规律!
来自主题: AI技术研报
5291 点击 2025-03-21 10:35
 搜索
搜索
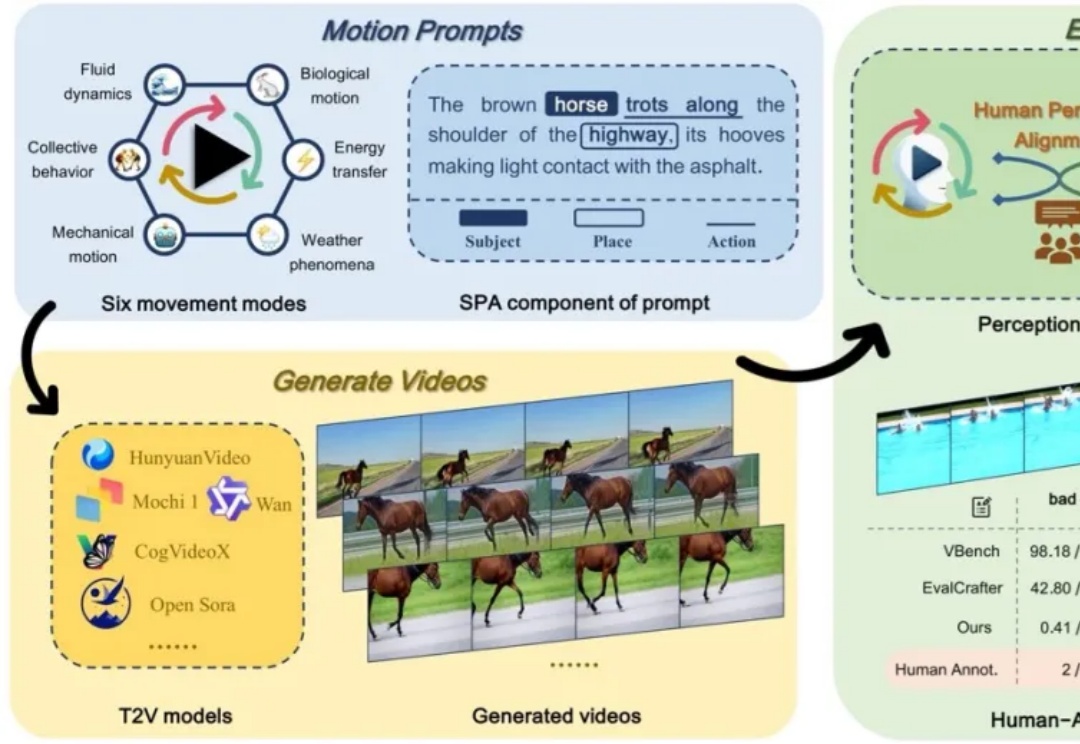
测一测现有AI生成视频是否符合物理运动规律!
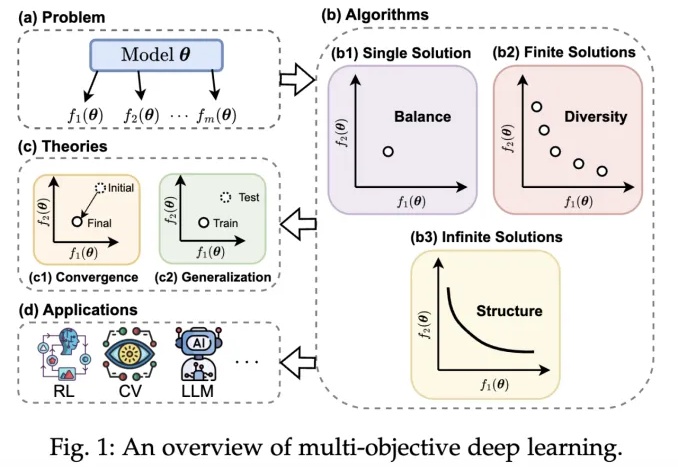
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。

在大模型逐步接近AGI之时,"AI对齐"一直被视为守护人类的最后一道防线。

跨模态因果对齐,让机器更懂视觉证据!

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。

StyleStudio能解决风格迁移中风格过拟合、文本对齐差和图像不稳定的问题,通过跨模态AdaIN技术融合文本和风格特征、用教师模型稳定布局、引入基于风格的无分类器引导,实现精准控制风格元素,提升生成图像的质量和稳定性,无需额外训练,使用门槛更低!

人类实现AGI之前,在技术、商业、治理方面仍然存在诸多问题——“人与AI能否共处” “算力叙事是否依然奏效” “开源有多大商业价值”等,腾讯科技策划《AGI之路》系列直播,联合合作伙伴,特邀专家、学者直播解读相关议题,对齐AGI共识,探寻AGI可行之路。
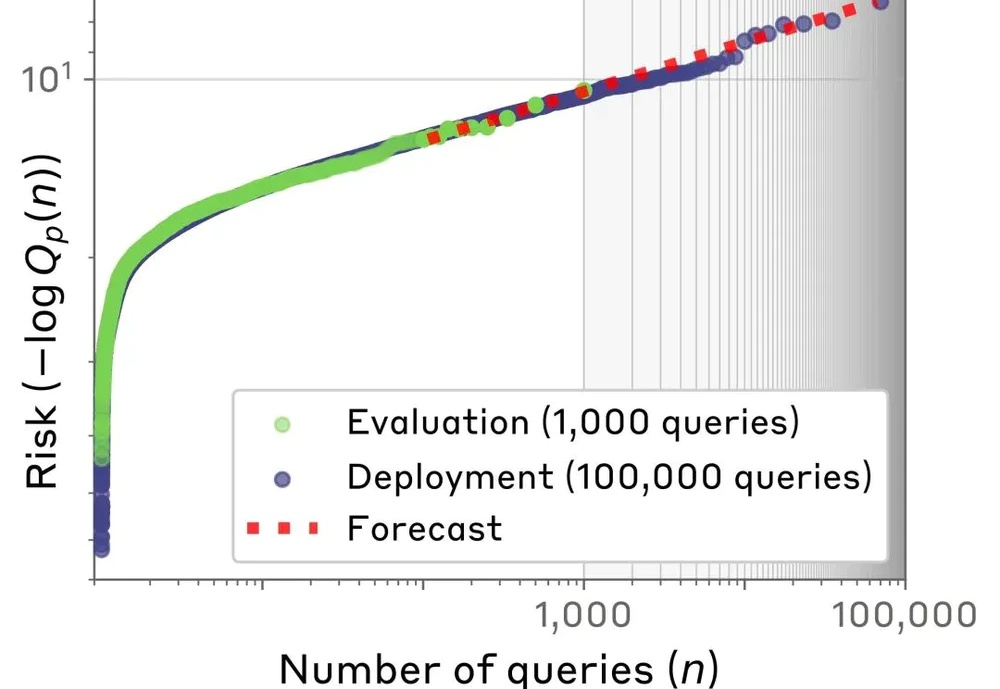
对齐科学的主要目标之一,是在危险行为发生之前,预测人工智能(AI)模型的危险行为倾向。
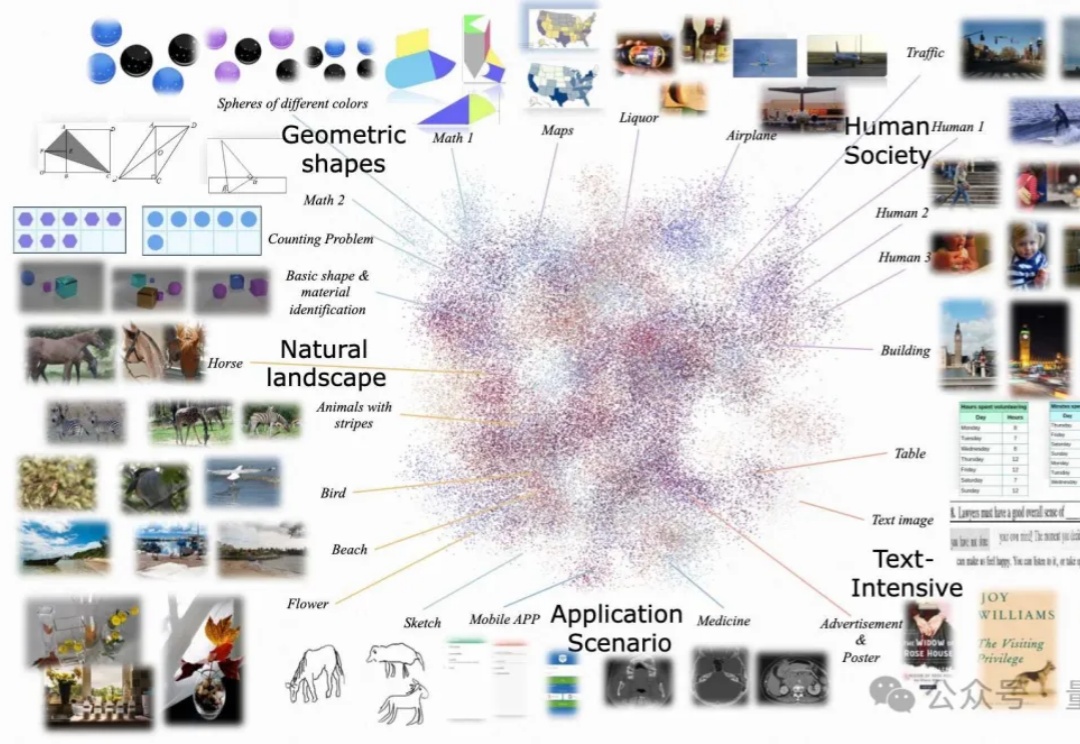
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。