
剪映产品负责人张逍然离职
剪映产品负责人张逍然离职《智能涌现》从多个独立信源获悉,剪映产品负责人张逍然目前已经离职。
来自主题: AI资讯
9811 点击 2024-12-30 15:18
 搜索
搜索
《智能涌现》从多个独立信源获悉,剪映产品负责人张逍然目前已经离职。
在人工智能快速发展的当下,这个问题有了新的答案——处理284张720P的图片。2023年12月,随着字节跳动发布最新的豆包视觉理解模型,AI领域又迎来一次"降维打击":每千tokens的输入价格降至3厘,较行业常见价格低了整整85%。

提起特斯拉、字节跳动这样的科技大厂你首先想到的是什么? 是马路上呼啸而过的新能源汽车? 还是改变娱乐方式的先进算法? 让所有人都没想到的是,这两家大厂最近“不务正业”般地把目光放在了“玩具”的身上。甚至还以此为蓝图,为我们盘开了一个千亿级的大市场。

前脚大模型六小虎之一的智谱刚完成新一轮30亿的融资;后脚字节跳动发布豆包视觉理解模型、快手可灵1.6正式上线。

蓝鲸新闻从多位知情人士处获悉,字节跳动TikTok算法负责人陈志杰或于近期离职,目前,他已经开启AI领域创业,知情人士称,陈志杰创业的方向为AI Coding方向,目前已经在陆续接触投资人。
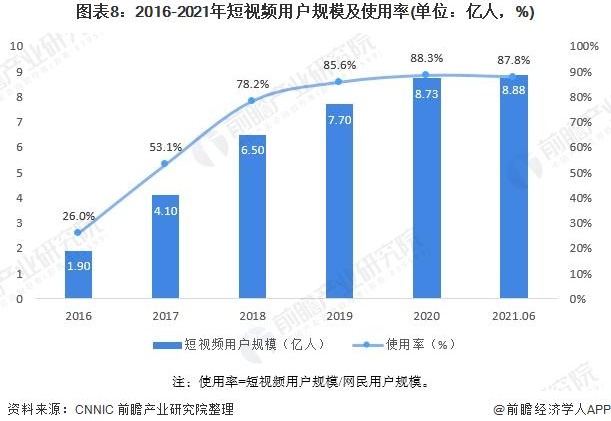
剪映成字节探索AI的利器

在大语言模型和 AIGC 的热潮下,科研人员对构建「视觉对话智能体」(Visual Chat Agent)展现出极大兴趣。其中,可实时交互的人像生成技术(Audio-Driven Real-Time Interactive Head Generation)是实现链路中极为关键的一环。

上周发出《AI时代写Prompt应该用APPL:为Prompt工程打造的编程语言,来自清华姚班的博士》之后,文章中实现了一个Google DeepMind的OPRO简单版本的优化方法,这让很多读者非常着迷。

当科技大厂卯足了劲要捣鼓出高大上的AI硬件时,一条看似不起眼的赛道杀了出来。
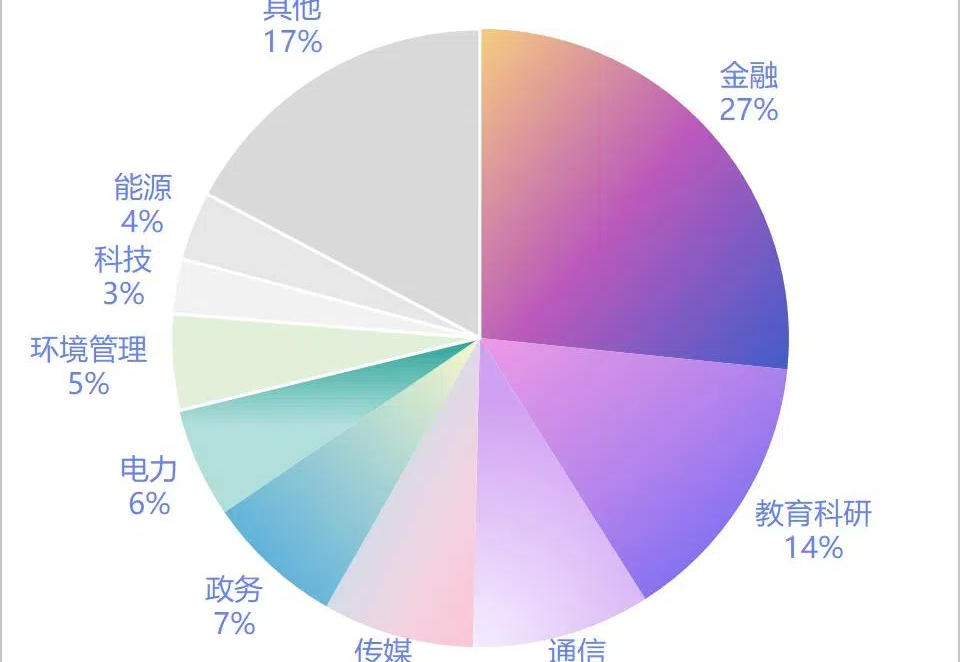
下半年订单金额增480% 大模型的竞争已经卷到商业化上了。