
GPT-4o竟是「道德专家」?解答50道难题,比纽约大学教授更受欢迎
GPT-4o竟是「道德专家」?解答50道难题,比纽约大学教授更受欢迎大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。
来自主题: AI技术研报
10378 点击 2024-07-05 16:30
 搜索
搜索
大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。

开源大语言模型(LLM)百花齐放,为了让它们适应各种下游任务,微调(fine-tuning)是最广泛采用的基本方法。基于自动微分技术(auto-differentiation)的一阶优化器(SGD、Adam 等)虽然在模型微调中占据主流,然而在模型越来越大的今天,却带来越来越大的显存压力。
马斯克连回两条推文为xAI造势,宣布8月发布Grok 2,年底将推出在10万张H100上训练的Grok 3,芯片加持创新数据训练,打造对标GPT的新一代大语言模型。
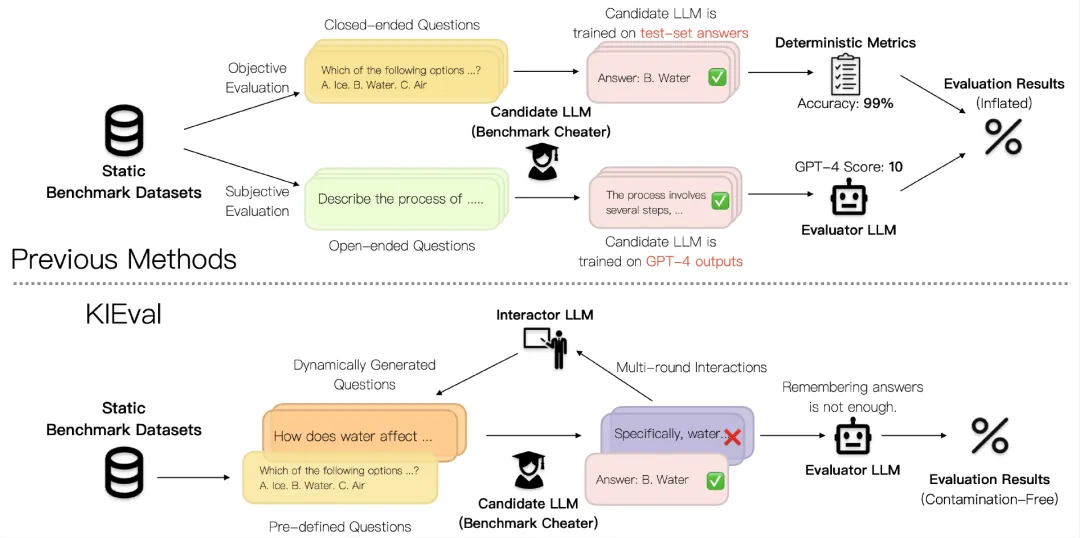
当前大语言模型(LLM)的评估方法受到数据污染问题的影响,导致评估结果被高估,无法准确反映模型的真实能力。北京大学等提出的KIEval框架,通过知识基础的交互式评估,克服了数据污染的影响,更全面地评估了模型在知识理解和应用方面的能力。

本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。

本文介绍了一篇语言模型对齐研究的论文,由瑞士、英国、和法国的三所大学的博士生和 Google DeepMind 以及 Google Research 的研究人员合作完成。

计算机程序可以生成很像真随机的「伪随机数」,而LLM表示,干脆不装了,我就有自己最喜欢的数。

本文关注OpenAI近期的两次收购,从这两次收购背后,试图拼起OpenAI设计“未来操作系统--LLMOS”的巨大蓝图。

大语言模型绝不会是通往AGI之路上的最后一个重大技术突破。

在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RLHF)来管理这些模型,成效显著,标志着向更加人性化 AI 迈出的关键一步。