
无问芯穹提出混合稀疏注意力方案MoA,加速长文本生成,实现最高8倍吞吐率提升
无问芯穹提出混合稀疏注意力方案MoA,加速长文本生成,实现最高8倍吞吐率提升随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。
来自主题: AI技术研报
5413 点击 2024-11-08 19:19
 搜索
搜索
随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。

在Prompt工程领域,规划任务一直以来都是一个巨大的挑战,因为这要求大语言模型(LLMs)不仅能够理解自然语言,还能有效执行复杂推理和应对长时间跨度的操作。

消除激活值(outliers),大语言模型低比特量化有新招了—— 自动化所、清华、港城大团队最近有一篇论文入选了NeurIPS 2024(Oral Presentation),他们针对LLM权重激活量化提出了两种正交变换,有效降低了outliers现象,达到了4-bit的新SOTA。
近日,伊利诺伊大学香槟分校的研究团队发布了一篇开创性论文,首次从理论层面证明了大语言模型(LLM)中的prompt机制具有图灵完备性。这意味着,通过合适的prompt设计,一个固定大小的Transformer模型理论上可以计算任何可计算函数。这一突破性发现为prompt工程提供了坚实的理论基础。

网络智能体旨在让一切基于网络功能的任务自动发生。比如你告诉智能体你的预算,它可以帮你预订酒店。既拥有海量常识,又能做长期规划的大语言模型(LLM),自然成为了智能体常用的基础模块。

算法设计(AD)对于各个领域的问题求解至关重要。大语言模型(LLMs)的出现显著增强了算法设计的自动化和创新,提供了新的视角和有效的解决方案。
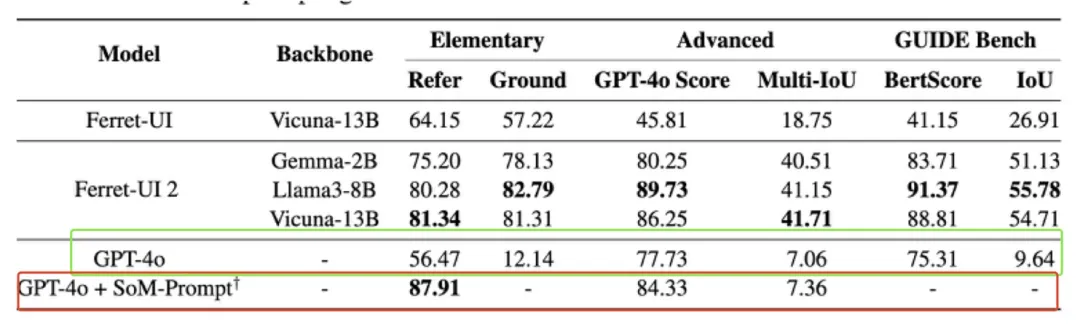
家人们,苹果一直在悄悄进步! 近期,据小鹿观察,各大科技巨头不仅在提升模型解决复杂问题的能力上竞争激烈,而且还在大语言模型应用于用户界面(UI)交互方面上暗暗发力!

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

在当前大语言模型(LLM)蓬勃发展的环境下,Prompt工程师们面临着一个两难困境:要么使用像LangChain这样功能强大但学习曲线陡峭的框架,要么选择自动化程度更高DSPy但牺牲了对提示词精确控制的工具。IBM研究院和UC Davis大学最近推出的PDL(Prompt Declaration Language,提示词声明语言)或许打破了这个困境,让AI开发者能真正拿回Prompt的控制权。
AI裁判通过反馈生成更公正报告,接近共识。