
NeurIPS 2024 | 智能体不够聪明怎么办?清华&蚂蚁团队:让它像学徒一样持续学习
NeurIPS 2024 | 智能体不够聪明怎么办?清华&蚂蚁团队:让它像学徒一样持续学习随着 ChatGPT 掀起的 AI 浪潮进入第三年,人工智能体(AI Agent)作为大语言模型(LLM)落地应用的关键载体,正受到学术界和产业界的持续关注。
来自主题: AI技术研报
8515 点击 2024-12-11 09:48
 搜索
搜索
随着 ChatGPT 掀起的 AI 浪潮进入第三年,人工智能体(AI Agent)作为大语言模型(LLM)落地应用的关键载体,正受到学术界和产业界的持续关注。

自从去年ChatGPT4出现以来,以大语言模型为主的AI和星舰一样,在中文网络上愈发被一些群体当成美国对中国的某种决战兵器而极尽吹捧。比如最近风头正盛的某“经济学家”一直在各种场合鼓吹AI将带领美国实现产业升级。

自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。
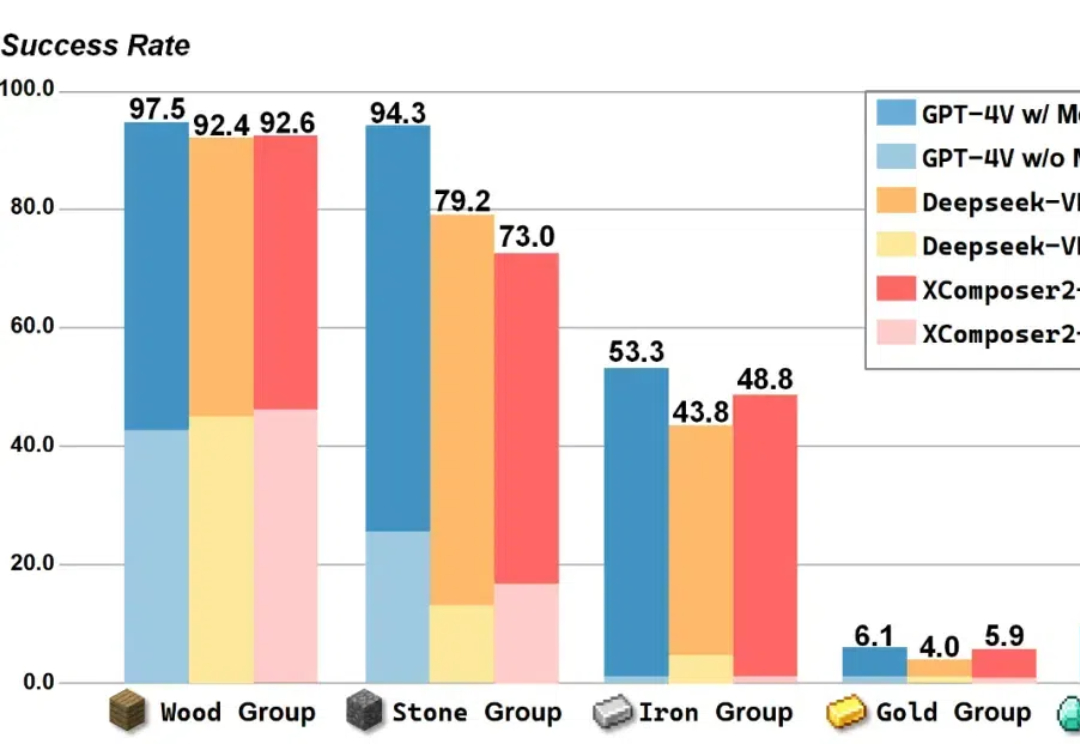
在 Minecraft 中构造一个能完成各种长序列任务的智能体,颇有挑战性。现有的工作利用大语言模型 / 多模态大模型生成行动规划,以提升智能体执行长序列任务的能力。
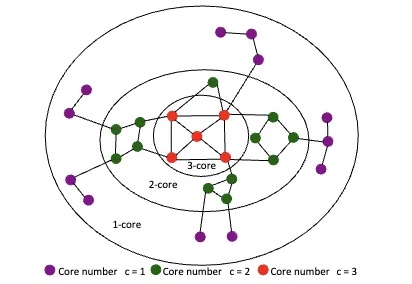
大语言模型直接理解复杂图结构的新方法来了:
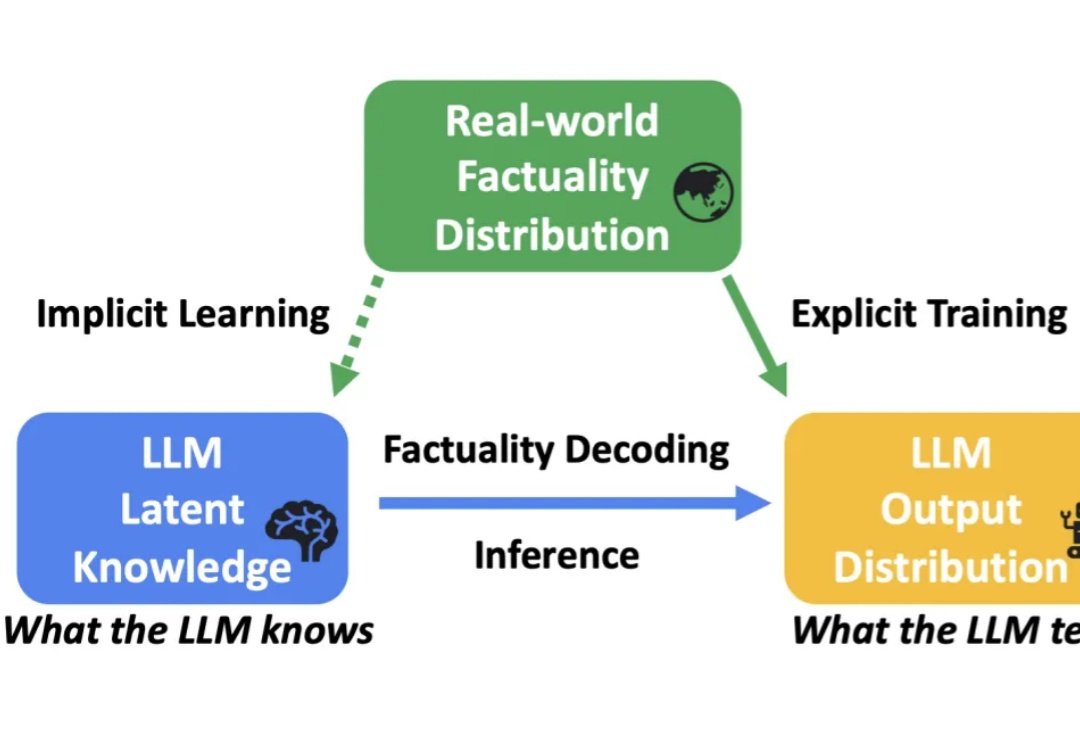
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
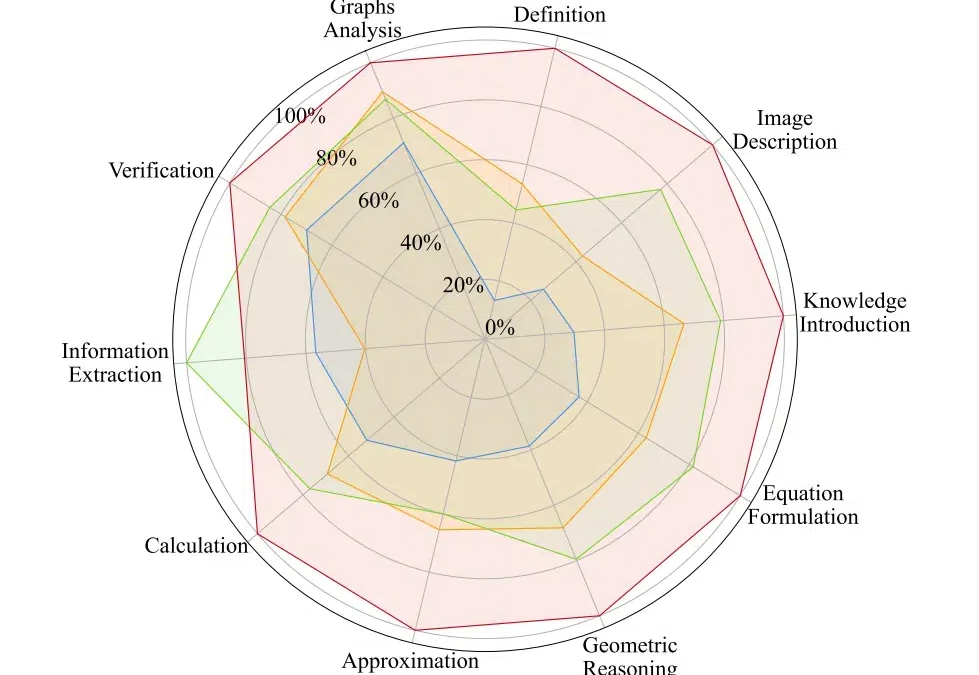
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。

当前,生成式AI正席卷整个社会,大语言模型(LLMs)在文本(ChatGPT)和图像(DALL-E)生成方面取得了令人惊叹的成就,仅仅依赖零星几个提示词,它们就能生成超出预期的内容

一家总部位于美国加州的初创公司Tilde,正在构建解释器模型,解读模型的推理过程,并通过引导采样动态调整生成策略,提升大语言模型的推理能力和生成精度。相比直接优化提示的提示工程,这一方法展现出更灵活高效的潜力,有望重塑AI交互方式。