
大模型正在从黄金时代进入白银时代
大模型正在从黄金时代进入白银时代越来越多人开始关注大模型,很多做工程开发的同学问我怎么入门大模型训练推理系统软件(俗称大模型Infra)。
来自主题: AI资讯
10652 点击 2024-08-16 20:52
 搜索
搜索
越来越多人开始关注大模型,很多做工程开发的同学问我怎么入门大模型训练推理系统软件(俗称大模型Infra)。

大模型作为当下 AI 工业界和学术界当之无愧的「流量之王」,吸引了大批学者和企业投入资源去研究与训练。随着规模越做越大,系统和工程问题已经成了大模型训练中绕不开的难题。例如在 Llama3.1 54 天的训练里,系统会崩溃 466 次,平均 2.78 小时一次!

HBM因AI大模型训练需求爆增,市场火热。
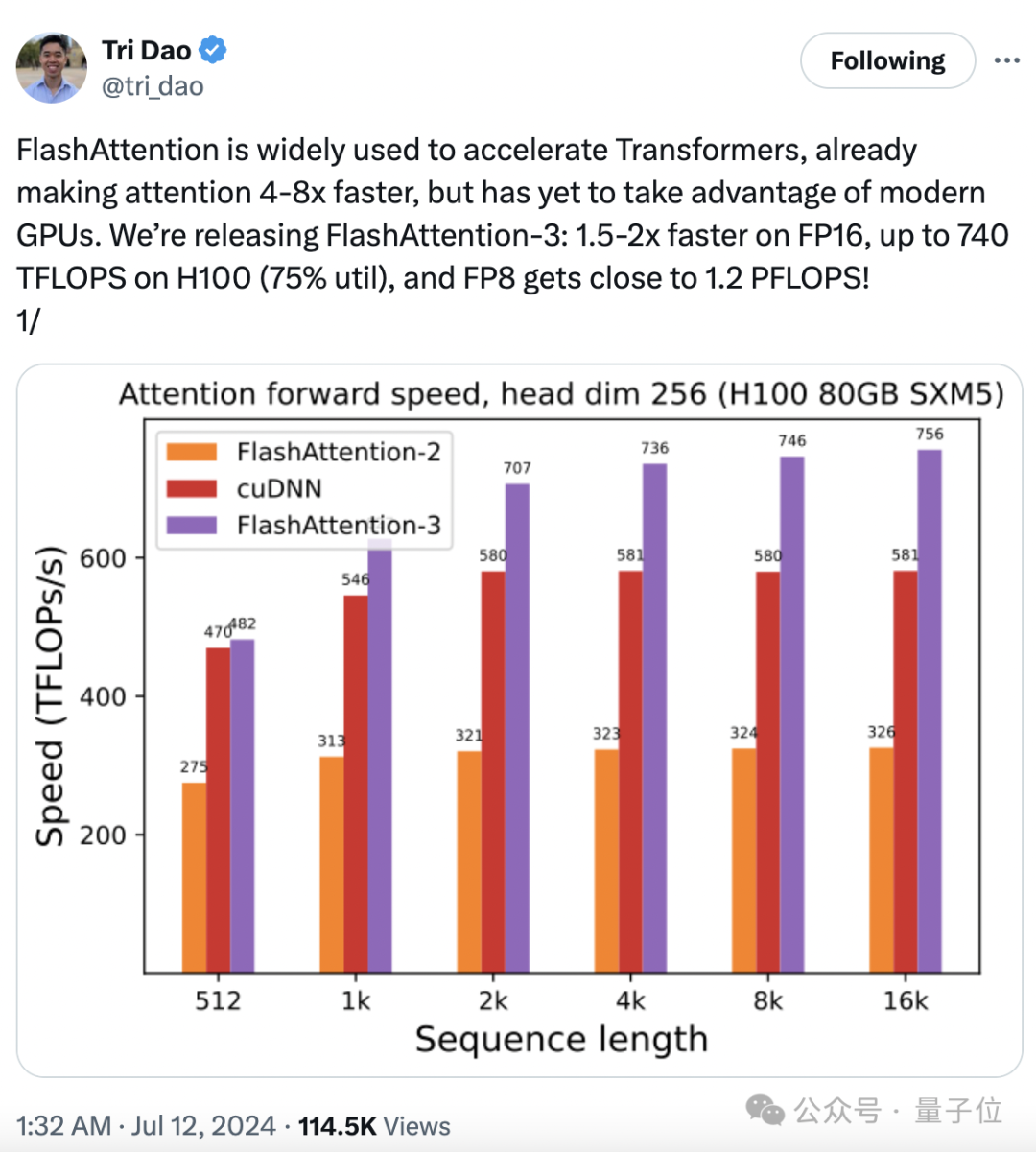
大模型训练推理神作,又更新了!

Anthropic首席执行官表示,当前AI模型训练成本是10亿美元,未来三年,这个数字可能会上升到100亿美元甚至1000亿美元。要知道,GPT-4o这个曾经最大的模型也只用了1亿美元。千亿美刀,究竟花在了哪里?

「原来以为语料已经匮乏了,大模型训练已经没有语料了,实际上不是的,数据还远远没有跑光」。

Alexandr Wang创办的Scale AI是一个为AI模型提供训练数据的数据标注平台,近期完成新一轮10亿美元融资,估值飙升至138亿美元。该公司表示将利用新资金生产丰富的前沿数据,为通向AGI铺平道路。

在上一篇文章「Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存」中,我们介绍了Unsloth,这是一个大模型训练加速和显存高效的训练框架,我们已将其整合到Firefly训练框架中,并且对Llama3-8B的训练进行了测试,Unsloth可大幅提升训练速度和减少显存占用。

AI发展驱动收入增长,但成本激增需大投资。

如何复盘大模型技术爆发的这一年?除了直观的感受,你还需要一份系统的总结