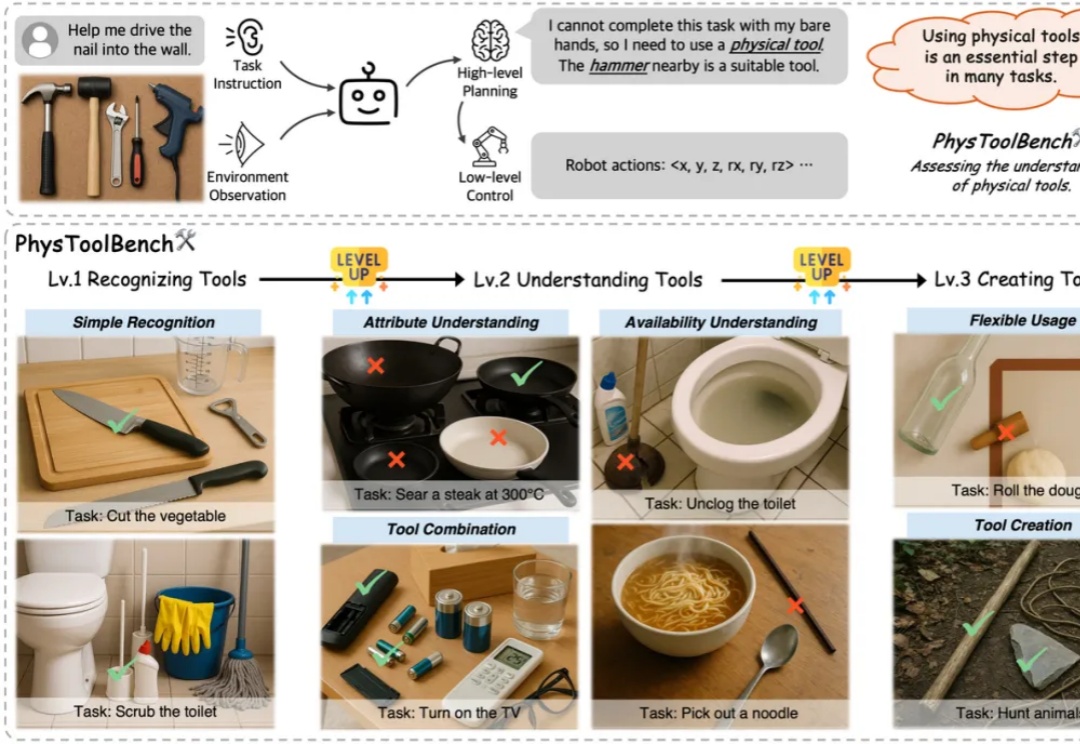
多模态大模型理解物理工具吗?PhysToolBench提出了衡量多模态大模型对物理工具理解的基准
多模态大模型理解物理工具吗?PhysToolBench提出了衡量多模态大模型对物理工具理解的基准人类之所以能与复杂的物理世界高效互动,很大程度上源于对「工具」的使用、理解与创造能力。对任何通用型智能体而言,这同样是不可或缺的基本技能,对物理工具的使用会大大影响任务的成功率与效率。
来自主题: AI技术研报
11315 点击 2025-11-05 09:57
 搜索
搜索
人类之所以能与复杂的物理世界高效互动,很大程度上源于对「工具」的使用、理解与创造能力。对任何通用型智能体而言,这同样是不可或缺的基本技能,对物理工具的使用会大大影响任务的成功率与效率。
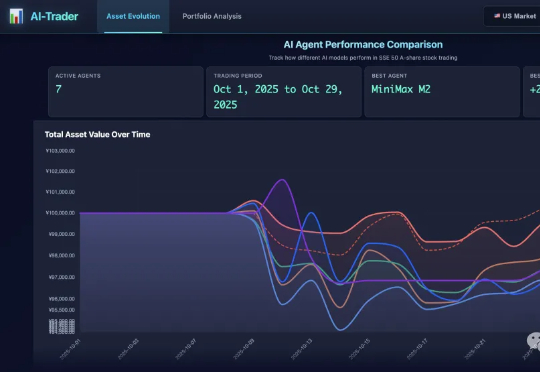
屠榜开源大模型的MiniMax M2是怎样炼成的?为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了? 面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。
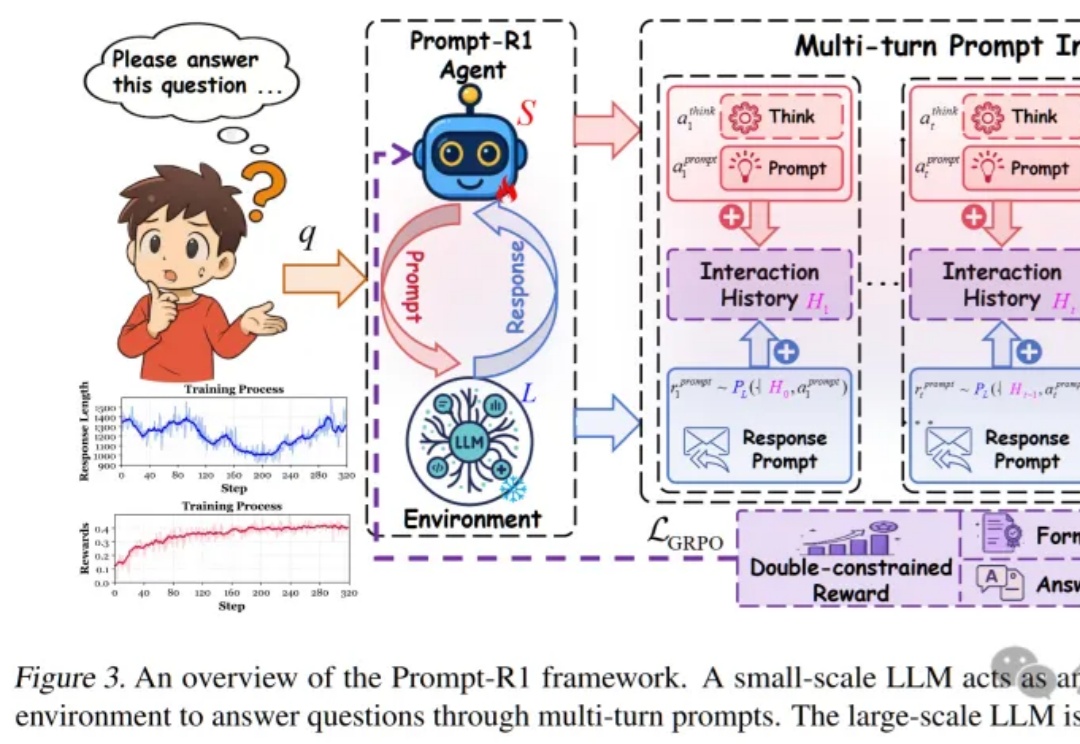
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。
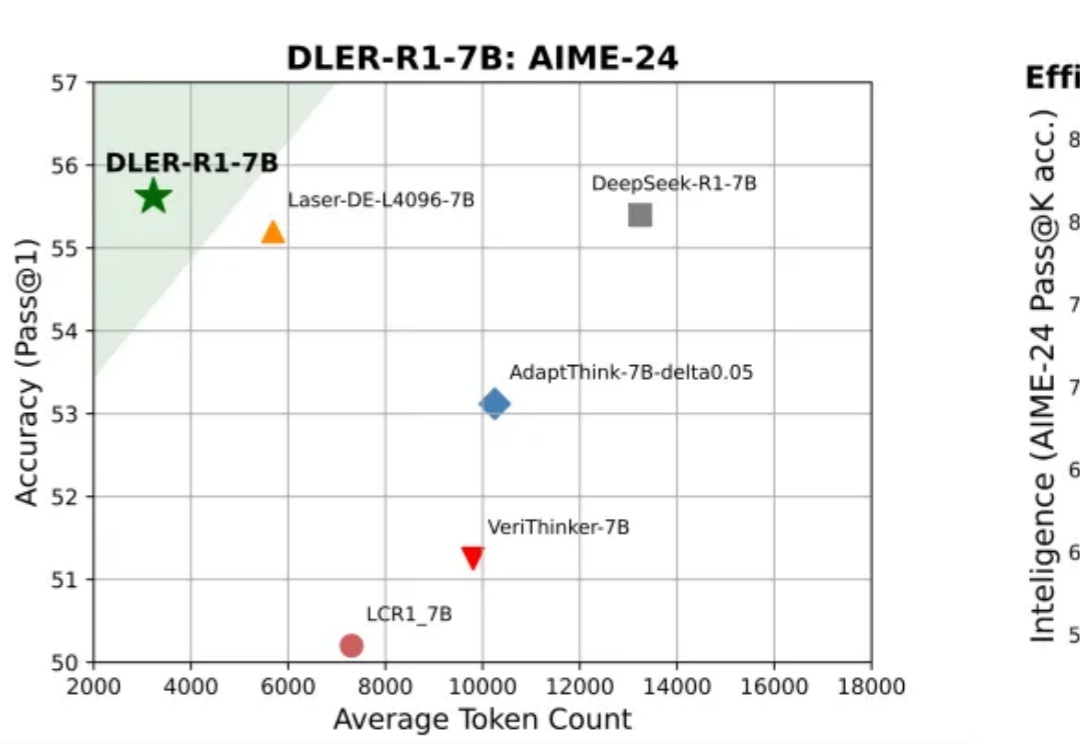
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。

昨天一大早,就发现美团开源了他们首款全模态实时交互大模型:LongCat-Flash-Omni。
是孩子该看的东西。

Transformer 语言模型具有单射性,隐藏状态可无损重构输入信息。

从豆包的「产品卡」里,可以窥见大模型对产品销售的新链路已经展开。

当你发现自己刷到的视频、帖子是「AI制造」时,当身边的人用一种「AI腔调」和你说话时,你是不是想要迅速滑走,或者直接拉黑?加州大学伯克利分校等机构的权威研究证实,AI正在改变我们的说话、写作等交流方式,让我们的交际「塑料感」十足。
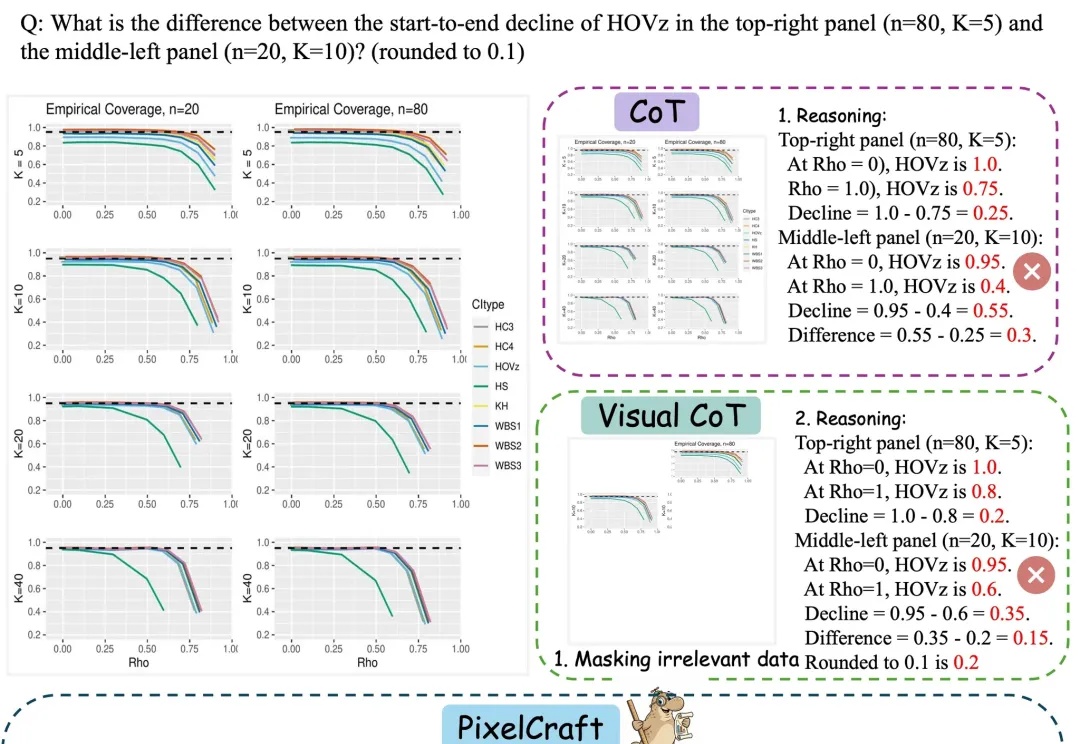
多模态大模型(MLLM)在自然图像上已取得显著进展,但当问题落在图表、几何草图、科研绘图等结构化图像上时,细小的感知误差会迅速放大为推理偏差。