
先解行为,再训Agent:CMU开源首份Agentic Search日志数据,把Agent拆开给你看
先解行为,再训Agent:CMU开源首份Agentic Search日志数据,把Agent拆开给你看在大模型驱动的 Agentic Search 日益常态化的背景下,真实环境中智能体 “如何发查询、如何改写、是否真正用上检索信息” 一直缺乏系统刻画与分析。
来自主题: AI技术研报
9011 点击 2026-02-09 14:55
 搜索
搜索
在大模型驱动的 Agentic Search 日益常态化的背景下,真实环境中智能体 “如何发查询、如何改写、是否真正用上检索信息” 一直缺乏系统刻画与分析。
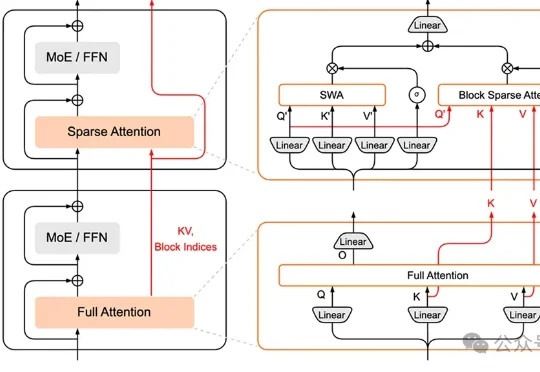
小米MiMo大模型团队,加入AI拜年战场——推出HySparse,一种面向Agent时代的混合稀疏注意力架构。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混

外网都在好奇: 全球模型服务平台 OpenRouter 上这个搜索第一的神秘模型是哪家的? 这个匿名模型叫做「Pony Alpha」。根据 OpenRouter 官方的说法,它是新一代的通用大模型,在编程、逻辑推理和角色扮演方面表现突出,并针对 Agent 工作流进行了优化,具有极高的工具调用准确率。

营销,正式进入 AI 时代。 近日,专注于答案引擎优化(AEO)的 AI Agent 平台 PallasAI 宣布完成数千万人民币融资,由香港上市公司有赞(8083.HK)独家投资。这是该公司三个月内

过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
大模型的革命行将结束,即将开启的会是物理 AI 时代?

2026 刚来到 2 月,无论是底层模型大厂还是初创公司统统加速开卷,其中 Agentic Memory 方向的快速进化更是把大模型的能力上限推向了 NEXT LEVEL!
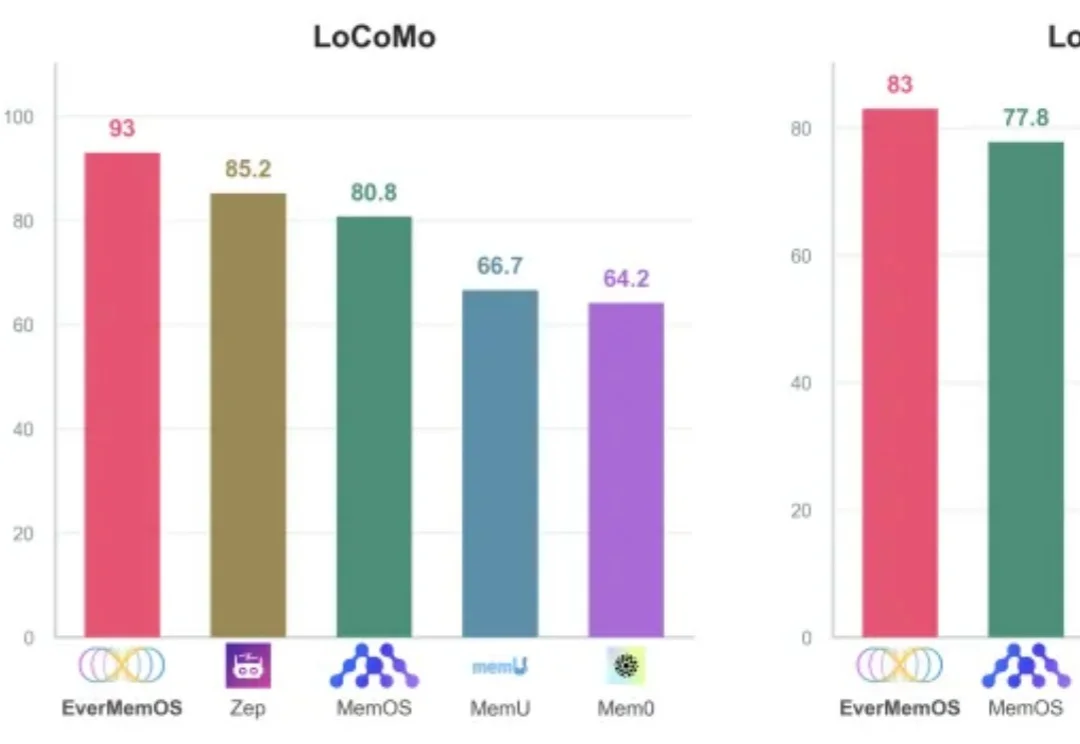
开年,DeepSeek论文火遍全网,内容聚焦大模型记忆。