DeepSeek新论文来了!联手清华、北大,优化智能体大模型推理
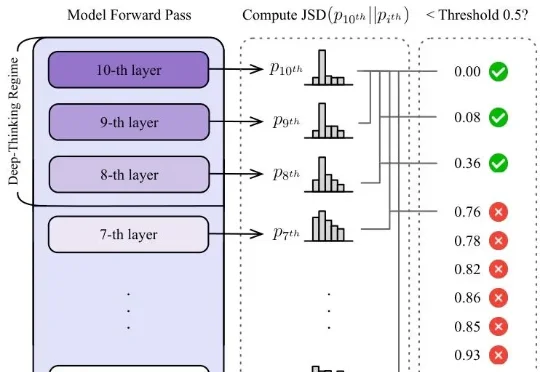
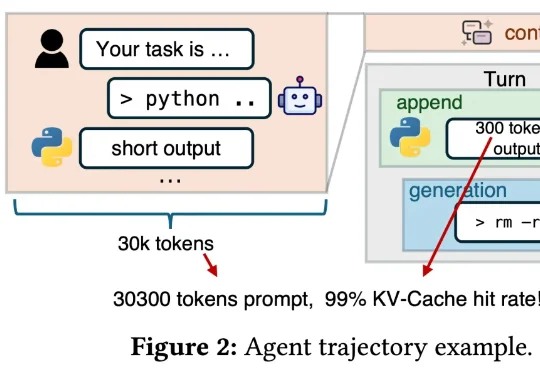
DeepSeek新论文来了!联手清华、北大,优化智能体大模型推理「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。
来自主题: AI技术研报
9174 点击 2026-02-27 11:35