
字节发布豆包大模型:主力模型价格国内最低,豆包App已成最大AI黑马
字节发布豆包大模型:主力模型价格国内最低,豆包App已成最大AI黑马整个 2023 年,字节并没有对外官宣其内部自研的大模型。外界一度认为,大模型这一技术变革,字节入场晚了。梁汝波在去年底的年会上也提到了这一点,他表示「字节对技术的敏感度不如创业公司,直到 2023 年才开始讨论 GPT。」
来自主题: AI资讯
11709 点击 2024-05-17 15:01
 搜索
搜索
整个 2023 年,字节并没有对外官宣其内部自研的大模型。外界一度认为,大模型这一技术变革,字节入场晚了。梁汝波在去年底的年会上也提到了这一点,他表示「字节对技术的敏感度不如创业公司,直到 2023 年才开始讨论 GPT。」
在谷歌巨大的商业化版图面前,单纯提前一天发布GPT-4o,似乎并没有给OpenAI带来足够的优势。

生成式AI时代,数据编织将成为下一代数据管理的主流范式。

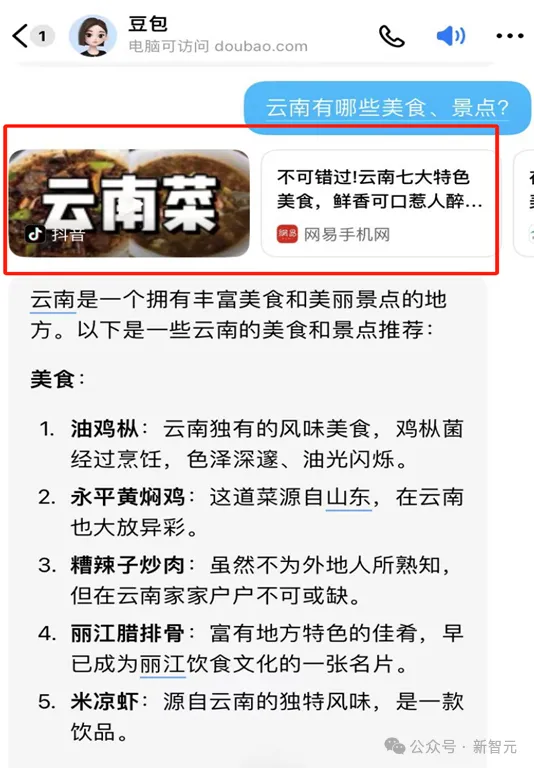
5月15日,在2024春季火山引擎Force原动力大会上,字节跳动自研豆包大模型正式亮相。

大模型落地较难,市场热情下降

国外卷技术,国内卷价格。

据悉,近日,成都海艺互娱“海艺绘画大模型”、晓多科技“晓模型XPT”、明途科技“MT-WorkGpt”3个大模型成功通过国家生成式人工智能服务备案,成都行业大模型实现国家网信办备案“零”突破。

在大型语言模型的训练过程中,数据的处理方式至关重要。

大模型带来的生命科学领域突破,刚刚再传新进展。
大模型正以前所未有的速度重塑我们的工作和生活方式,人们期待大模型走向千行百业,为实际业务带来真正的价值提升。