
硅谷团队抄袭清华系大模型?面壁智能李大海独家回应:套壳现象难规避
硅谷团队抄袭清华系大模型?面壁智能李大海独家回应:套壳现象难规避抄袭框架和预训练数据的情况,是更狭义的套壳。
来自主题: AI资讯
10886 点击 2024-06-05 09:56
 搜索
搜索
抄袭框架和预训练数据的情况,是更狭义的套壳。
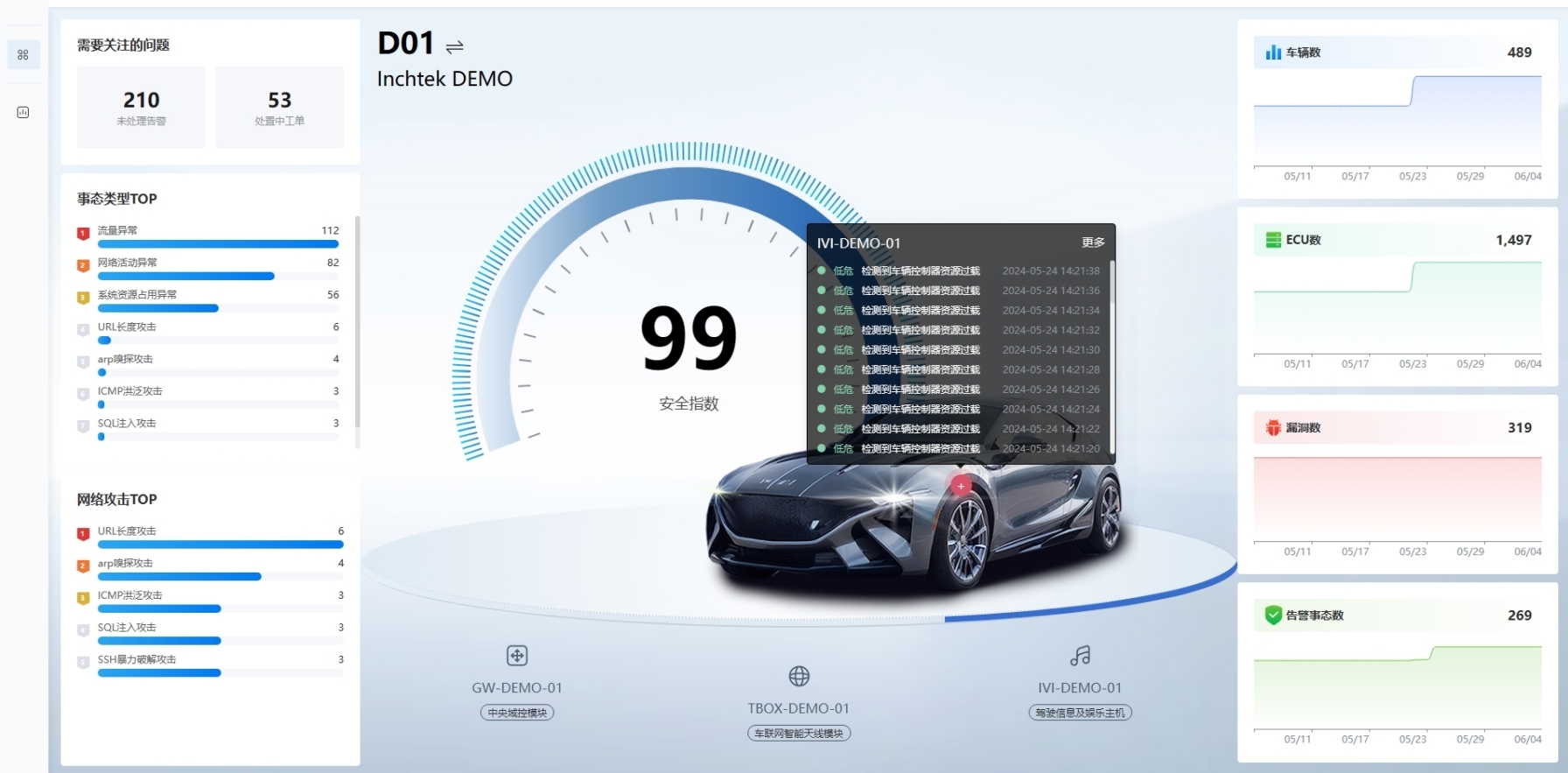
云驰未来inVSOC让网络安全防护更加高效、智能,为汽车网络安全保驾护航。

大模型开始“普世化”了,不必理解技术,在不知不觉中就能用得不亦乐乎。
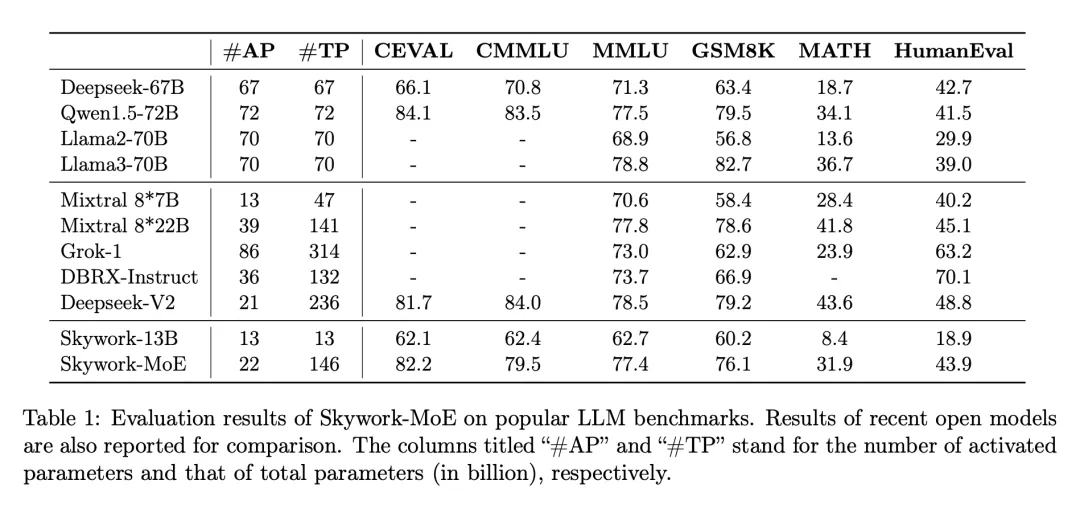
在大模型浪潮中,训练和部署最先进的密集 LLM 在计算需求和相关成本上带来了巨大挑战,尤其是在数百亿或数千亿参数的规模上。为了应对这些挑战,稀疏模型,如专家混合模型(MoE),已经变得越来越重要。这些模型通过将计算分配给各种专门的子模型或「专家」,提供了一种经济上更可行的替代方案,有可能以极低的资源需求达到甚至超过密集型模型的性能。

自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。
只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!
大模型,大,能力强,好用!
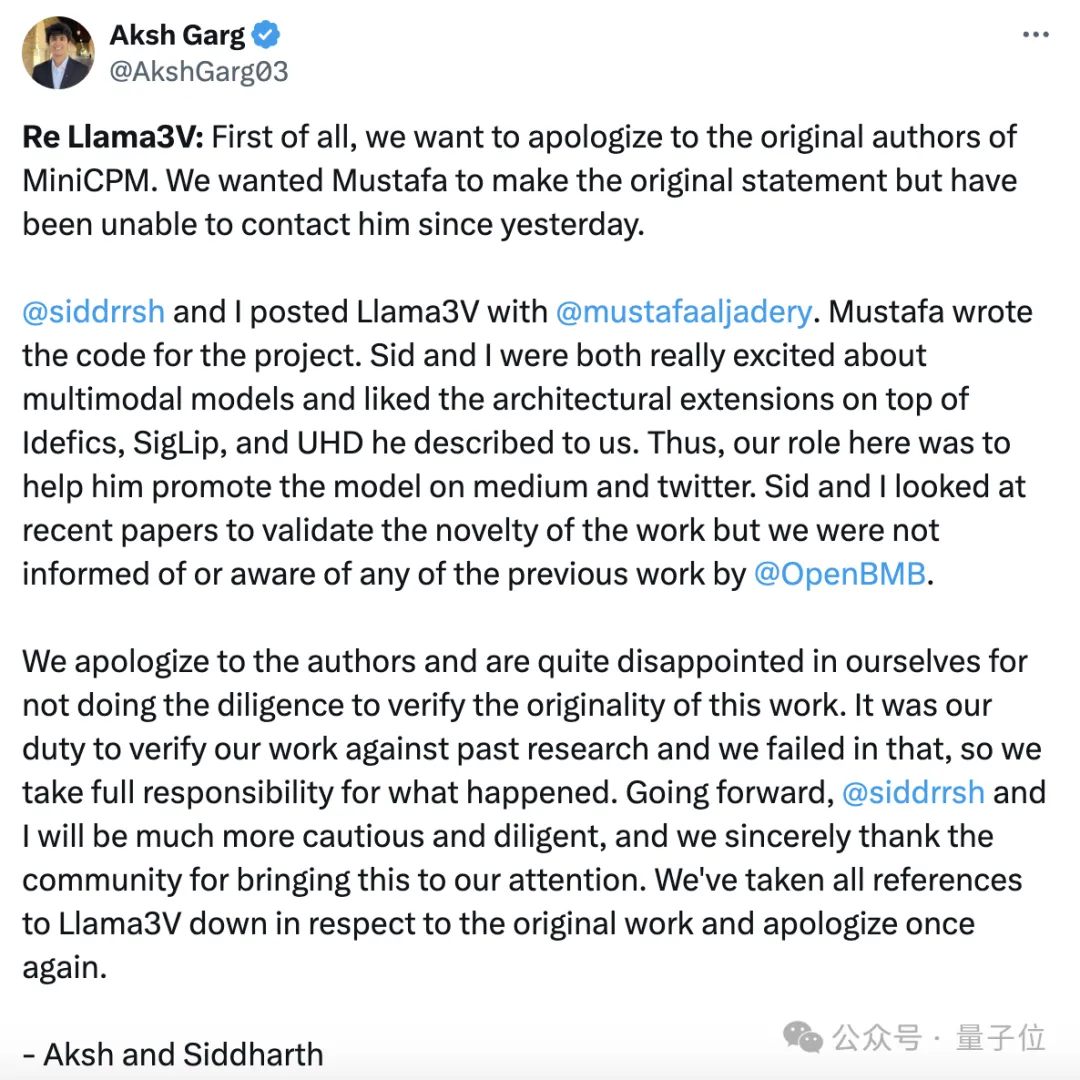
斯坦福团队抄袭清华系大模型事件后续来了—— Llama3-V团队承认抄袭,其中两位来自斯坦福的本科生还跟另一位作者切割了。

6 月 2 日,英伟达创始人黄仁勋在 Computex 2024(2024 台北国际电脑展)上发表主题演讲,分享了人工智能时代如何助推全球新产业革命,并且展示了最新的 Blackwell 芯片和后续的一系列更新节奏。

面壁智能回应:“深表遗憾”,这也是一种“受到国际团队认可的方式”。