
李沐重返母校,上交大秒变追星现场,大模型趋势无保留分享
李沐重返母校,上交大秒变追星现场,大模型趋势无保留分享什么是顶流?
来自主题: AI资讯
11123 点击 2024-08-24 16:18
 搜索
搜索
什么是顶流?

《黑神话:悟空》上线之后,各大资讯平台出现一批奇怪文章。它们开篇讲“震惊”,全文说“震撼”,然而没评测、没细节、没结论,如大圣爷毫毛化猴,面目雷同又空空如也,最后汇入百亿流量之中。

昆仑万维上半年业绩强劲,AI业务多点开花。

端侧大模型的真实需求仍需验证。

从尝到甜头到回到巅峰,还需几步?
“在AI最火热的时候,我写了本小说。”

大模型进入“应用爆发元年”,落地再次成为AI竞速关键词。

以 GPT 为代表的大型语言模型预示着数字认知空间中通用人工智能的曙光。这些模型通过处理和生成自然语言,展示了强大的理解和推理能力,已经在多个领域展现出广泛的应用前景。无论是在内容生成、自动化客服、生产力工具、AI 搜索、还是在教育和医疗等领域,大型语言模型都在不断推动技术的进步和应用的普及。

代码知识原来这么重要。
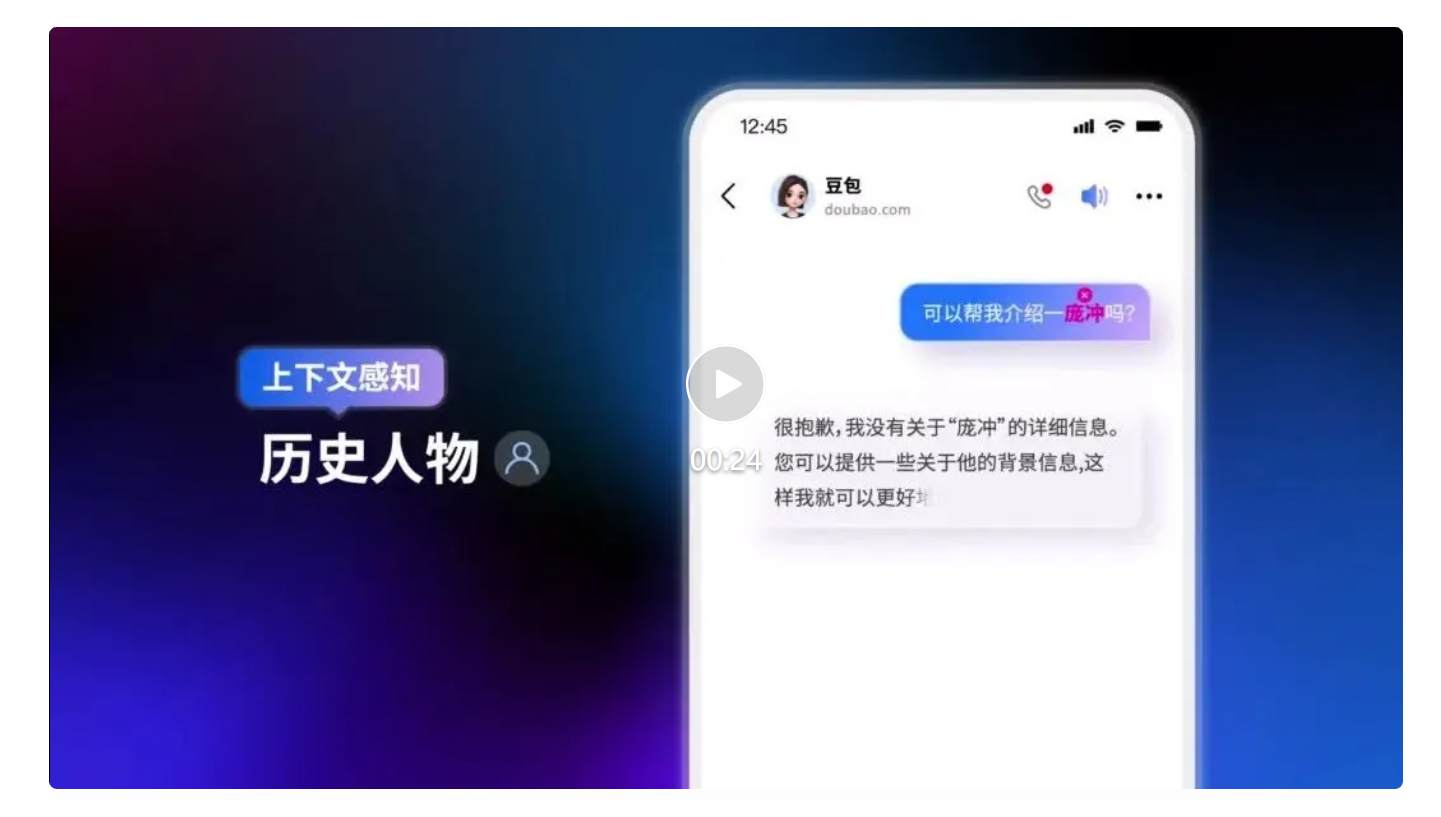
8 月 21 日,2024 火山引擎 AI 创新巡展﹒上海站带来了豆包大模型最新进展。