
金融科技公司这半年:转型寻路、押注AI、探索出海
金融科技公司这半年:转型寻路、押注AI、探索出海回望我国上半年的消费市场,一个最大的关键词是增长。
来自主题: AI资讯
7177 点击 2024-08-28 15:25
 搜索
搜索
回望我国上半年的消费市场,一个最大的关键词是增长。

OpenAI 传说中的「Strawberry(草莓)」模型终于要来了。

从上代AI延伸过来的智能电梯,智能音箱;类似Her的产品;写作AI智能体;基于AIGC的SEO工具;具身机器人;医疗大模型;微软的Copilot。
大模型API,正式进入Flash时代。

佐思汽研发布《2024年车载AI Agent产品开发与商业化研究报告》。

AI 科技评论独家获悉,字节跳动正在秘密筹备成立大模型研究院,并积极招揽人才。
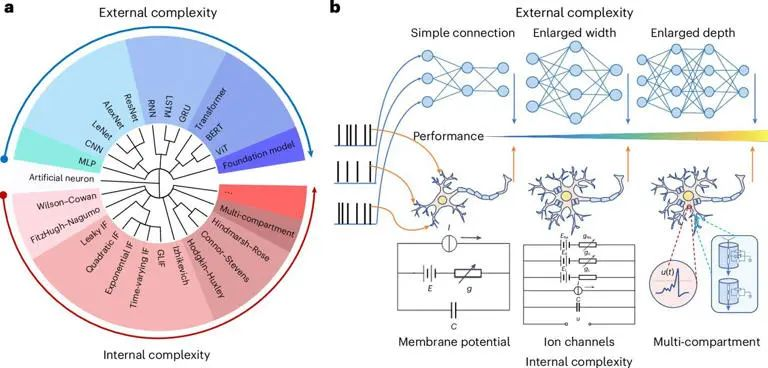
人工智能,AI,大模型,神经网络

睡觉做梦,大脑实际上会运行一个内部“世界模型”!

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。
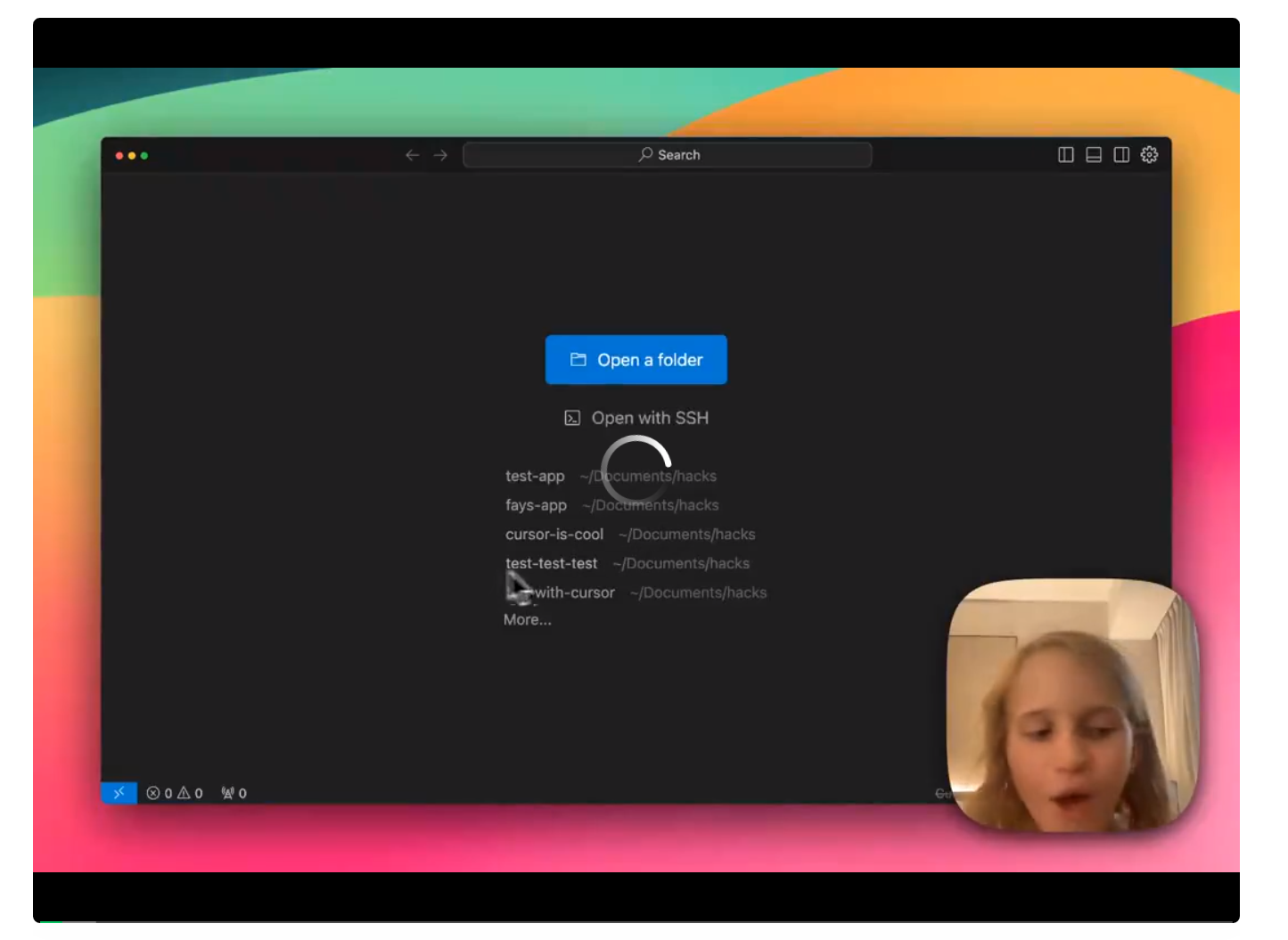
关于大模型,大厂们最近在卷什么,最新消息是:AI编程工具。