全球3.5亿下载量破纪录! Llama家族暴涨10倍,开源帝国掀AI革命
全球3.5亿下载量破纪录! Llama家族暴涨10倍,开源帝国掀AI革命诞生一年半,Llama家族早已稳坐开源界头把交椅。最新报告称,Llama全球下载量近3.5亿,是去年同期的10倍。而模型开源让每个人最深体会是,token价格一降再降。
来自主题: AI资讯
8354 点击 2024-08-30 20:44
 搜索
搜索
诞生一年半,Llama家族早已稳坐开源界头把交椅。最新报告称,Llama全球下载量近3.5亿,是去年同期的10倍。而模型开源让每个人最深体会是,token价格一降再降。
在人工智能科技行业,实在智能以其自研的通用人工智能(AGI)大模型和超自动化技术,占据了重要的市场地位,并在人机协同领域展现出稳健的发展势头。
OpenAI估值,超1000亿美元!
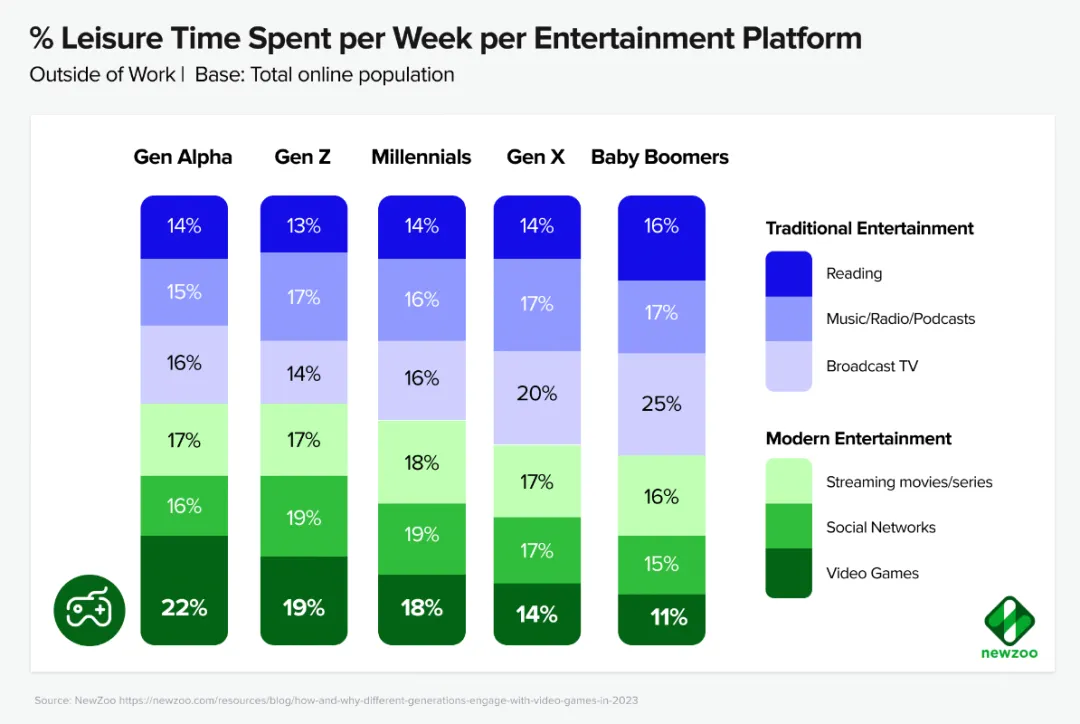
技术的进步,会直接带来内容生产方式和消费方式的变革。
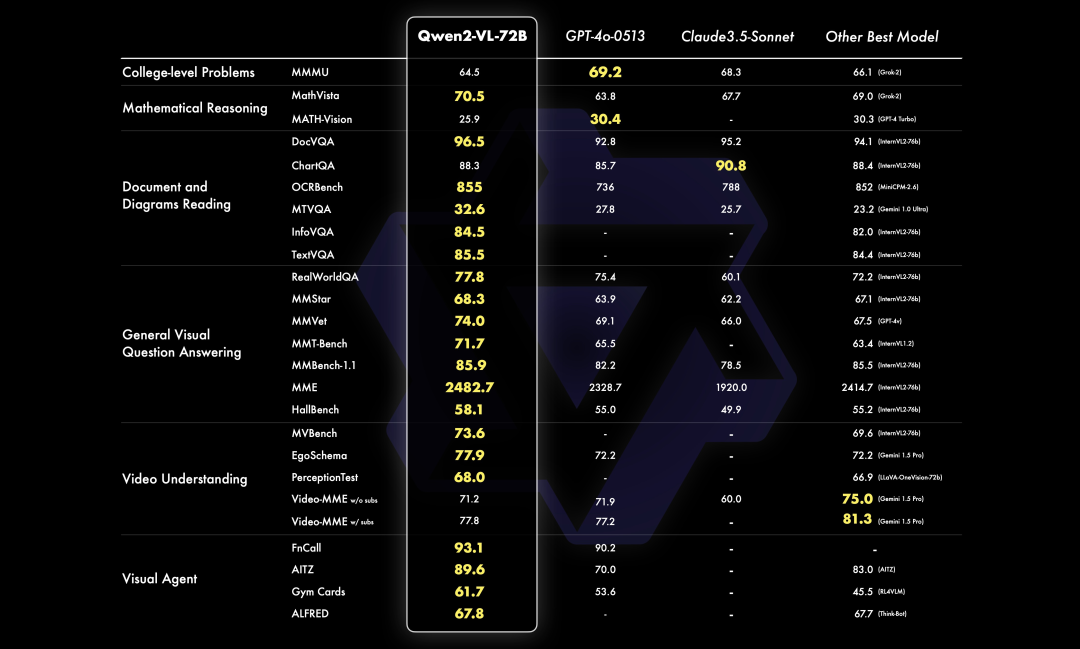
新的最强开源多模态大模型来了!

人工智能正在帮助人类深度认识月球。

现有的大模型已经能够创作令人惊叹画作,那鉴赏艺术画作岂不是信手拈来?
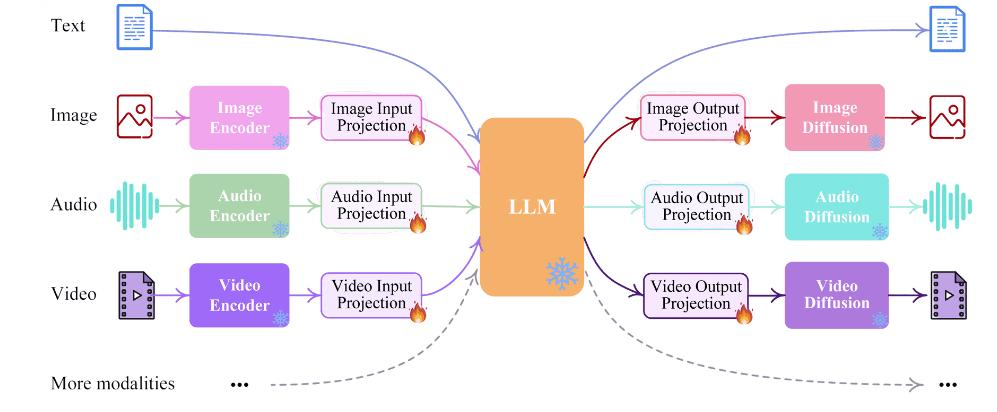
在体验上越来越接近人与人的自然交流。
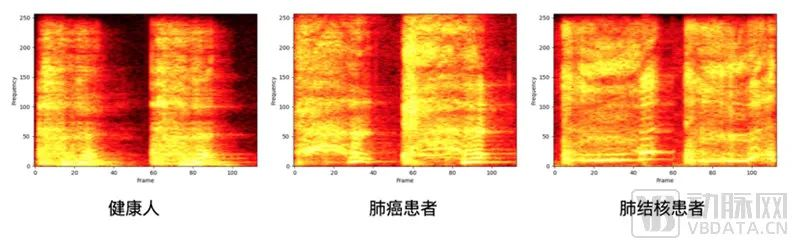
通过患者体内发出的声音“听音辨病”成为现实又近了一步
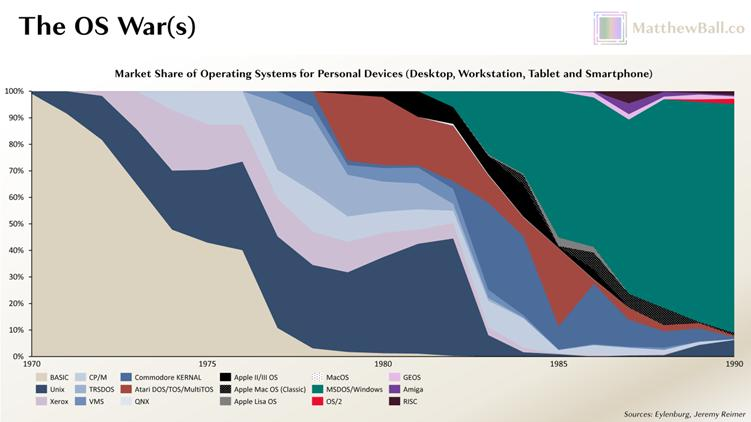
市场有不确定性,但微软的成功是确定的